本文是应用《从Docker到Kubernetes》的实验内容。
实验环境延续Kubernets部署
POD pod是kubernets中最小的调度单位,控制器是用于管理pod。
创建与删除 # 查看当前namespace中的pod [root@kmaster ~]# kubectl get pods No resources found in nssec namespace. # 查看kube-system下的pod [root@kmaster ~]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-78d6f96c7b-667pc 1/1 Running 9 25d calico-node-f7mkg 1/1 Running 10 25d calico-node-gbwp5 1/1 Running 9 25d calico-node-zs7hn 1/1 Running 9 25d coredns-59d64cd4d4-hpnvx 1/1 Running 9 25d coredns-59d64cd4d4-pzqmh 1/1 Running 9 25d etcd-kmaster 1/1 Running 9 25d kube-apiserver-kmaster 1/1 Running 4 14d kube-controller-manager-kmaster 1/1 Running 10 25d kube-proxy-55g52 1/1 Running 10 25d kube-proxy-ft62b 1/1 Running 9 25d kube-proxy-w4l64 1/1 Running 9 25d kube-scheduler-kmaster 1/1 Running 10 25d metrics-server-c44f75469-8rslv 1/1 Running 6 19d # 查看所有namespace中的pod [root@kmaster ~]# kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE default recycler-for-pv02 0/1 Completed 0 14d kube-system calico-kube-controllers-78d6f96c7b-667pc 1/1 Running 9 25d kube-system calico-node-f7mkg 1/1 Running 10 25d kube-system calico-node-gbwp5 1/1 Running 9 25d kube-system calico-node-zs7hn 1/1 Running 9 25d kube-system coredns-59d64cd4d4-hpnvx 1/1 Running 9 25d kube-system coredns-59d64cd4d4-pzqmh 1/1 Running 9 25d kube-system etcd-kmaster 1/1 Running 9 25d kube-system kube-apiserver-kmaster 1/1 Running 4 14d kube-system kube-controller-manager-kmaster 1/1 Running 10 25d kube-system kube-proxy-55g52 1/1 Running 10 25d kube-system kube-proxy-ft62b 1/1 Running 9 25d kube-system kube-proxy-w4l64 1/1 Running 9 25d kube-system kube-scheduler-kmaster 1/1 Running 10 25d kube-system metrics-server-c44f75469-8rslv 1/1 Running 6 19d kubernetes-dashboard dashboard-metrics-scraper-c45b7869d-stzd4 1/1 Running 9 25d kubernetes-dashboard kubernetes-dashboard-576cb95f94-z8hww 1/1 Running 6 19d nsvolume nfs-client-provisioner-79bb64c666-h6kcn 1/1 Running 3 14d # 创建pod # --image=镜像名 --port=端口 --labels=标签=值 --image-pull-policy=always(每次下载镜像)/IfNotPresent(优先使用本地镜像) [root@kmaster ~]# kubectl run pod1 --image=nginx --port=8080 --image-pull-policy=IfNotPresent --labels=version=1.21 pod/pod1 created # 查看已创建pod [root@kmaster ~]# kubectl get pods NAME READY STATUS RESTARTS AGE pod1 1/1 Running 0 11s # 查看pod所在主机 [root@kmaster ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod1 1/1 Running 0 16s 10.244.195.171 knode1 <none> <none> # 查看pod1的属性 [root@kmaster ~]# kubectl describe pod pod1 Name: pod1 Namespace: nssec Priority: 0 Node: knode1/192.168.10.11 Start Time: Tue, 19 Sep 2023 18:54:37 +0800 Labels: version=1.21 Annotations: cni.projectcalico.org/podIP: 10.244.195.171/32 cni.projectcalico.org/podIPs: 10.244.195.171/32 Status: Running IP: 10.244.195.171 IPs: IP: 10.244.195.171 Containers: pod1: Container ID: docker://660e39cbc44b22add327a929049cee18345d0af529bcfb4600878528428ba145 Image: nginx Image ID: docker-pullable://nginx@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31 Port: 8080/TCP Host Port: 0/TCP State: Running Started: Tue, 19 Sep 2023 18:54:38 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-6brs8 (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: kube-api-access-6brs8: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s node.kubernetes.io/unreachable:NoExecute op=Exists for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m12s default-scheduler Successfully assigned nssec/pod1 to knode1 Normal Pulled 2m12s kubelet Container image "nginx" already present on machine Normal Created 2m12s kubelet Created container pod1 Normal Started 2m12s kubelet Started container pod1 # 删除pod [root@kmaster ~]# kubectl delete pod pod1 pod "pod1" deleted # 创建pod的yaml格式文本 # --dry-run=client 模拟创建 -o yaml以yaml格式输出创建动作 [root@kmaster pod]# kubectl run pod1 --image=nginx --dry-run=client -o yaml --image-pull-policy=IfNotPresent > pod1-build.yaml # 实施yaml文件 [root@kmaster pod]# kubectl apply -f pod1-build.yaml pod/pod1 created [root@kmaster pod]# kubectl get pods NAME READY STATUS RESTARTS AGE pod1 1/1 Running 0 11s # 以文件形式删除pod [root@kmaster pod]# kubectl delete -f pod1-build.yaml pod "pod1" deleted # yaml文件解析 [root@kmaster pod]# cat pod1-build.yaml apiVersion: v1 # 执行pod的api version,固定值为v1 kind: Pod # 指定当前yaml要创建的类型是pod metadata: # 指定pod的元数据信息,包括pod名称、标签、命名空间等 creationTimestamp: null labels: run: pod1 name: pod1 # pod名称 spec: # 定义容器和策略 containers: # 定义容器 - image: nginx # 指定镜像 imagePullPolicy: IfNotPresent # 镜像下载策略,always总是下载,never从不下载,只用本地,IfNotPresent优先本地 name: pod1 resources: {} # 定义资源限制 dnsPolicy: ClusterFirst # 定义DNS测率 restartPolicy: Always # 自动启动pod策略 status: {}
基本操作 # 执行pod中容器的命令 [root@kmaster pod]# kubectl apply -f pod1.yaml pod/pod1 created [root@kmaster pod]# kubectl exec pod1 -- ls /usr/share/nginx/html 50x.html index.html # 向pod中复制文件 [root@kmaster pod]# kubectl cp /etc/hosts pod1:/usr/share/nginx/html [root@kmaster pod]# kubectl exec pod1 -- ls /usr/share/nginx/html 50x.html hosts index.html # 进入pod中并获取bash [root@kmaster pod]# kubectl exec -it pod1 -- bash root@pod1:/# ls bin boot dev docker-entrypoint.d docker-entrypoint.sh etc home # pod中有多个容器,指定容器名称,进入pod # 通过describe描述获得pod名称 [root@kmaster pod]# kubectl exec -it pod2 -c c2 -- bash root@pod2:/# exit # 获取pod日志输出 [root@kmaster pod]# kubectl logs pod2 error: a container name must be specified for pod pod2, choose one of: [pod2 c2] [root@kmaster pod]# kubectl logs pod2 -c c2 /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/ /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh # 删除同一个yaml文件创建的多容器pod [root@kmaster pod]# kubectl delete -f pod2.yaml pod "pod2" deleted
生命周期 宽限期 删除pod时,默认会有30秒的宽限期,称为terminating,可以通过terminationGracePeriodSecond来定义。
apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pod0 name: pod0 spec: terminationGracePeriodSeconds: 15 # 设定删除延时为15秒 containers: - image: busybox imagePullPolicy: Never name: pod0 command: ["sh","-c","sleep 1000"] # pod运行为1000秒,下达删除命令后15秒删除,不等到1000秒 dnsPolicy: ClusterFirst restartPolicy: Always status: {}
钩子 在pod的生命周期内,有两个hook可用
postStart:当创建pod时,会随pod的主进程运行,没有先后顺序
postStop:当删除pod时,要先运行preStop中的程序,之后再关闭pod
如果preStop在宽限期内没有完成,则强制删除pod
apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pod3 name: pod3 spec: terminationGracePeriodSeconds: 600 # 设定600秒的宽限期 containers: - image: nginx imagePullPolicy: IfNotPresent name: pod3 resources: {} lifecycle: # 生命周期参数 preStop: # 停止前操作 exec: # 执行命令 command: ["/bin/sh","-c","/usr/bin/nginx -s quit"] # 退出nginx进程 dnsPolicy: ClusterFirst restartPolicy: Always status: {}
初始化 包含多个容器的pod,需要配置容器的启动顺序才能运行,这就是pod的初始化。如果任一个初始化容器执行失败,则普通容器不会运行,如果定义多个初始化容器,则后续初始化容器不再执行。普通容器之后在初始化容器正确运行完毕并退出之后才会运行。
# 部署Nginx之前先修改主机的swapiness值 apiVersion: v1 kind: Pod metadata: labels: run: pod3 name: pod3 spec: containers: - image: nginx # 普通容器 imagePullPolicy: IfNotPresent name: c1 resources: {} initContainers: # 配置初始化容器 - image: docker.io/alpine:latest # 初始化容器为alpine name: swapvalue # 容器名称 imagePullPolicy: IfNotPresent command: ["/bin/sh","-c","/sbin/sysctl -w vm.swappiness=10"] # 执行对物理机操作,修改物理机内核参数 securityContext: # 默认容器不允许修改物理机内核参数,需要添加安全上下文 privileged: true resources: {} dnsPolicy: ClusterFirst restartPolicy: Always status: {}
# 部署Nginx之前,挂载存储路径 apiVersion: v1 kind: Pod metadata: name: myapp labels: run: myapp spec: volumes: # 配置存储卷 - name: workdir # 名称 emptyDir: {} # 存储卷为空目录 containers: - name: podx # 普通容器 image: nginx imagePullPolicy: IfNotPresent volumeMounts: - name: workdir mountPath: "/data" # 存储卷挂载目录为/data initContainers: - name: poda # 初始化容器 image: busybox # 容器镜像 imagePullPolicy: IfNotPresent command: ['sh', '-c', 'touch /work-dir/aa.txt'] # 创建文件 volumeMounts: - name: workdir mountPath: "/work-dir" # 将存储卷挂载到poda容器的/work-dir目录 dnsPolicy: ClusterFirst restartPolicy: Always
静态Pod 正常情况下,pod在master上统一管理、指定、分配。静态pod时指不是由master创建启动,而是在node上预先配置,启动kubelet之后,随之自动创建的pod。
# 创建pod的yaml存储目录 [root@knode1 ~]# mkdir /etc/kubernetes/kubelet.d # 在Node上编辑kubelet服务文件 # 在Service栏目的Environment参数后添加指定yaml文件存放目录 --pod-manifest-path=/etc/kubernetes/kubelet.d [root@knode1 ~]# vim /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf [Service] Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf --pod-manifest-path=/etc/kubernetes/kubelet.d" Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml" …… # 重启服务 [root@knode1 ~]# systemctl daemon-reload [root@knode1 ~]# systemctl restart kubelet [root@knode1 ~]# vim /etc/kubernetes/kubelet.d/web.yaml # 创建yaml文件 apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: role: myrole name: static-web spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: web resources: {} dnsPolicy: ClusterFirst restartPolicy: Always status: {} # 在master节点上查看pod,已经自动创建 [root@kmaster ~]# kubectl get pods -n default NAME READY STATUS RESTARTS AGE static-web-knode1 1/1 Running 0 3m12s [root@kmaster ~]# kubectl get pods -n default -o wide NAME READY STATUS RESTARTS AGE IP NODE static-web-knode1 1/1 Running 0 5m5s 10.244.195.177 knode1 [root@kmaster ~]# kubectl describe pod static-web-knode1 -n default Name: static-web-knode1 Namespace: default Priority: 0 Node: knode1/192.168.10.11 Labels: role=myrole # 在knode1上删除yaml文件,则会自动删除pod [root@knode1 kubelet.d]# mv web.yaml ~ mv: overwrite ‘/root/web.yaml’? y [root@kmaster ~]# kubectl get pods -n default -o wide No resources found in default namespace.
在master主机上添加静态pod的路径为:
# 该文件路径非必要不建议修改,容易导致K8s启动失败 [root@kmaster ~]# cd /etc/kubernetes/manifests/ # 存储系统pod启动的yaml文件 [root@kmaster manifests]# ls etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
指定Pod运行位置 给节点设置标签 # 查看所有Node节点的标签值 [root@kmaster ~]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS kmaster Ready control-plane,master 27d v1.21.14 …… knode1 Ready worker1 27d v1.21.14 …… knode2 Ready worker2 27d v1.21.14 …… # 只查看Knode2节点的标签值 [root@kmaster ~]# kubectl get nodes knode2 --show-labels NAME STATUS ROLES AGE VERSION LABELS knode2 Ready worker2 27d v1.21.14 …… # 给Knode1设定diskxx=ssdxx标签 [root@kmaster ~]# kubectl label node knode1 diskxx=ssdxx node/knode1 labeled # 查看标签生效情况 [root@kmaster ~]# kubectl get nodes knode1 --show-labels NAME STATUS ROLES AGE VERSION LABELS knode1 Ready worker1 27d v1.21.14 ……,diskxx=ssdxx,…… # 删除标签,标签之后加减号 - [root@kmaster ~]# kubectl label node knode1 diskxx- node/knode1 labeled # 给所有节点添加标签 [root@kmaster ~]# kubectl label node --all diskxx=ssdxx node/kmaster labeled node/knode1 labeled node/knode2 labeled # 删除所有节点共有标签 [root@kmaster ~]# kubectl label node --all diskxx- node/kmaster labeled node/knode1 labeled node/knode2 labeled
创建在特定节点上运行的pod 在pod中通过nodeSelector可以让pod在含有特定标签的节点上运行。
# 创建knode1节点标签 [root@kmaster ~]# kubectl label node knode1 diskxx=ssdxx node/knode1 labeled # 配置yaml文件 [root@kmaster pod]# cat podlabel.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: role: myrole name: web1 spec: nodeSelector: # pod选择在diskxx=ssdxx标签的节点上运行 diskxx: ssdxx containers: - image: nginx imagePullPolicy: IfNotPresent name: web1 resources: {} dnsPolicy: ClusterFirst restartPolicy: Always status: {} [root@kmaster pod]# kubectl apply -f podlabel.yaml pod/web1 created # pod运行在knode1上 [root@kmaster pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web1 1/1 Running 0 13s 10.244.195.180 knode1 <none> <none>
Annotations(注释)设置 不管是node还是pod,包括其他对象,均包括一个Annotations属性,相当于注释
[root@kmaster pod]# kubectl describe nodes knode1 Name: knode1 Roles: worker1 Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux diskxx=ssdxx kubernetes.io/arch=amd64 kubernetes.io/hostname=knode1 kubernetes.io/os=linux node-role.kubernetes.io/worker1= node-role.kubernets.io/worker1= Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock node.alpha.kubernetes.io/ttl: 0 projectcalico.org/IPv4Address: 192.168.10.11/24 projectcalico.org/IPv4IPIPTunnelAddr: 10.244.195.128 volumes.kubernetes.io/controller-managed-attach-detach: true # 设定Annotation [root@kmaster pod]# kubectl annotate nodes knode1 dog=wangcai node/knode1 annotated [root@kmaster pod]# kubectl describe nodes knode1 Name: knode1 Roles: worker1 Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux diskxx=ssdxx kubernetes.io/arch=amd64 kubernetes.io/hostname=knode1 kubernetes.io/os=linux node-role.kubernetes.io/worker1= node-role.kubernets.io/worker1= Annotations: dog: wangcai kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock # 删除annotations [root@kmaster pod]# kubectl annotate nodes knode1 dog- node/knode1 annotated
节点管理 节点的cordon 如果某个节点要进行维护,希望节点不再被分配pod,则可以使用cordon将节点标记为不可调度,但已有pod还将运行在该节点上。
# 创建三副本deployment [root@kmaster pod]# cat d1.yaml apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: nginx name: nginx spec: replicas: 3 # 设置3副本策略 selector: matchLabels: app: nginx strategy: {} template: metadata: creationTimestamp: null labels: app: nginx spec: containers: - image: nginx name: nginx imagePullPolicy: IfNotPresent resources: {} status: {} [root@kmaster pod]# kubectl apply -f d1.yaml deployment.apps/nginx created # 创建3节点pod [root@kmaster pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-cxbxg 1/1 Running 0 11s 10.244.69.251 knode2 <none> <none> nginx-7cf7d6dbc8-j7x76 1/1 Running 0 11s 10.244.195.182 knode1 <none> <none> nginx-7cf7d6dbc8-ww4fm 1/1 Running 0 11s 10.244.195.181 knode1 <none> <none> # 将knode2节点设为不可调度 [root@kmaster pod]# kubectl cordon knode2 node/knode2 cordoned # 查看节点情况,调度被禁用 [root@kmaster pod]# kubectl get nodes NAME STATUS ROLES AGE VERSION kmaster Ready control-plane,master 27d v1.21.14 knode1 Ready worker1 27d v1.21.14 knode2 Ready,SchedulingDisabled worker2 27d v1.21.14 # pod分布情况不变 [root@kmaster pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-cxbxg 1/1 Running 0 100s 10.244.69.251 knode2 <none> <none> nginx-7cf7d6dbc8-j7x76 1/1 Running 0 100s 10.244.195.182 knode1 <none> <none> nginx-7cf7d6dbc8-ww4fm 1/1 Running 0 100s 10.244.195.181 knode1 <none> <none> # 手动将副本数扩展到6个 [root@kmaster pod]# kubectl scale deployment nginx --replicas=6 deployment.apps/nginx scaled # 新增pod将不会被调度到knode2上 [root@kmaster pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-28gdb 1/1 Running 0 3s 10.244.195.185 knode1 <none> <none> nginx-7cf7d6dbc8-cxbxg 1/1 Running 0 2m7s 10.244.69.251 knode2 <none> <none> nginx-7cf7d6dbc8-g9jpw 1/1 Running 0 3s 10.244.195.183 knode1 <none> <none> nginx-7cf7d6dbc8-j7x76 1/1 Running 0 2m7s 10.244.195.182 knode1 <none> <none> nginx-7cf7d6dbc8-rp44w 1/1 Running 0 3s 10.244.195.184 knode1 <none> <none> nginx-7cf7d6dbc8-ww4fm 1/1 Running 0 2m7s 10.244.195.181 knode1 <none> <none> # 手动删除原有knode2上的pod [root@kmaster pod]# kubectl delete pod nginx-7cf7d6dbc8-cxbxg pod "nginx-7cf7d6dbc8-cxbxg" deleted # 新拉起pod也同样被调度到knode1上 [root@kmaster pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-28gdb 1/1 Running 0 40s 10.244.195.185 knode1 <none> <none> nginx-7cf7d6dbc8-g9jpw 1/1 Running 0 40s 10.244.195.183 knode1 <none> <none> nginx-7cf7d6dbc8-j7x76 1/1 Running 0 2m44s 10.244.195.182 knode1 <none> <none> nginx-7cf7d6dbc8-rp44w 1/1 Running 0 40s 10.244.195.184 knode1 <none> <none> nginx-7cf7d6dbc8-vgqwh 1/1 Running 0 9s 10.244.195.186 knode1 <none> <none> nginx-7cf7d6dbc8-ww4fm 1/1 Running 0 2m44s 10.244.195.181 knode1 <none> <none> # 取消不可调度状态 [root@kmaster pod]# kubectl uncordon knode2 node/knode2 uncordoned # 节点状态恢复 [root@kmaster pod]# kubectl get nodes NAME STATUS ROLES AGE VERSION kmaster Ready control-plane,master 27d v1.21.14 knode1 Ready worker1 27d v1.21.14 knode2 Ready worker2 27d v1.21.14 # 删除nginx多副本deploy [root@kmaster pod]# kubectl scale deployment nginx --replicas=0 deployment.apps/nginx scaled
节点的drain 对节点的drain操作和对节点的cordon操作作用一致,但多了一个驱逐的效果,也就是不仅可以标识为不可调度,同时将删除正在运行的pod。
# 创建6副本pod [root@kmaster pod]# kubectl apply -f d1.yaml deployment.apps/nginx configured [root@kmaster pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-46n62 1/1 Running 0 4s 10.244.195.130 knode1 <none> <none> nginx-7cf7d6dbc8-4kmg2 1/1 Running 0 4s 10.244.195.191 knode1 <none> <none> nginx-7cf7d6dbc8-bsp5g 1/1 Running 0 4s 10.244.69.253 knode2 <none> <none> nginx-7cf7d6dbc8-tppxg 1/1 Running 0 4s 10.244.69.252 knode2 <none> <none> nginx-7cf7d6dbc8-v6tr2 1/1 Running 0 4s 10.244.69.254 knode2 <none> <none> nginx-7cf7d6dbc8-wp5kq 1/1 Running 0 4s 10.244.195.190 knode1 <none> <none> # 设置knode2为不可调度节点,忽略daemonsetpod并删除本地数据 [root@kmaster pod]# kubectl drain knode2 --ignore-daemonsets --delete-local-data Flag --delete-local-data has been deprecated, This option is deprecated and will be deleted. Use --delete-emptydir-data. node/knode2 already cordoned WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-f7mkg, kube-system/kube-proxy-55g52 evicting pod nssec/nginx-7cf7d6dbc8-v6tr2 evicting pod kube-system/coredns-59d64cd4d4-pzqmh evicting pod kube-system/metrics-server-c44f75469-8rslv evicting pod nssec/nginx-7cf7d6dbc8-bsp5g evicting pod kubernetes-dashboard/kubernetes-dashboard-576cb95f94-z8hww evicting pod nssec/nginx-7cf7d6dbc8-tppxg evicting pod kubernetes-dashboard/dashboard-metrics-scraper-c45b7869d-stzd4 I0920 23:05:03.722014 102522 request.go:668] Waited for 1.084529418s due to client-side throttling, not priority and fairness, request: GET:https://192.168.10.10:6443/api/v1/namespaces/kubernetes-dashboard/pods/kubernetes-dashboard-576cb95f94-z8hww pod/coredns-59d64cd4d4-pzqmh evicted pod/kubernetes-dashboard-576cb95f94-z8hww evicted pod/nginx-7cf7d6dbc8-bsp5g evicted pod/nginx-7cf7d6dbc8-v6tr2 evicted pod/metrics-server-c44f75469-8rslv evicted pod/nginx-7cf7d6dbc8-tppxg evicted pod/dashboard-metrics-scraper-c45b7869d-stzd4 evicted node/knode2 evicted # pod自动迁移到knode1上 [root@kmaster pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-46n62 1/1 Running 0 3m31s 10.244.195.130 knode1 <none> <none> nginx-7cf7d6dbc8-4kmg2 1/1 Running 0 3m31s 10.244.195.191 knode1 <none> <none> nginx-7cf7d6dbc8-ckn4f 1/1 Running 0 13s 10.244.195.133 knode1 <none> <none> nginx-7cf7d6dbc8-hxskw 1/1 Running 0 13s 10.244.195.132 knode1 <none> <none> nginx-7cf7d6dbc8-wp5kq 1/1 Running 0 3m31s 10.244.195.190 knode1 <none> <none> nginx-7cf7d6dbc8-zfxk7 1/1 Running 0 13s 10.244.195.129 knode1 <none> <none> # 取消drain操作,命令和cordon一样是uncordon [root@kmaster pod]# kubectl uncordon knode2 node/knode2 uncordoned
节点的污点及pod的污点容忍 默认pod不运行到master节点,是因为该节点存在taint(污点),只有设置了tolerations(容忍污点)的pod才能运行在该节点上。
# 查看Master节点的污点设置 [root@kmaster pod]# kubectl describe nodes kmaster |grep -E '(Role|Taints)' Roles: control-plane,master Taints: node-role.kubernetes.io/master:NoSchedule # 查看Worker节点的污点设置为none [root@kmaster pod]# kubectl describe nodes knode1 |grep -E '(Role|Taints)' Roles: worker1 Taints: <none>
给节点设置以及删除taint # 配置knode1污点 [root@kmaster pod]# kubectl taint nodes knode1 keyxx=valuexx:NoSchedule node/knode1 tainted # 利用上章节的deployment nginx都处于knode1节点状态,可见设置污点不影响当前运行pod [root@kmaster pod]# kubectl get pods -o wide --no-headers nginx-7cf7d6dbc8-46n62 1/1 Running 0 18m 10.244.195.130 knode1 <none> <none> nginx-7cf7d6dbc8-4kmg2 1/1 Running 0 18m 10.244.195.191 knode1 <none> <none> nginx-7cf7d6dbc8-ckn4f 1/1 Running 0 15m 10.244.195.133 knode1 <none> <none> nginx-7cf7d6dbc8-hxskw 1/1 Running 0 15m 10.244.195.132 knode1 <none> <none> nginx-7cf7d6dbc8-wp5kq 1/1 Running 0 18m 10.244.195.190 knode1 <none> <none> nginx-7cf7d6dbc8-zfxk7 1/1 Running 0 15m 10.244.195.129 knode1 <none> <none> [root@kmaster pod]# kubectl get nodes NAME STATUS ROLES AGE VERSION kmaster Ready control-plane,master 27d v1.21.14 knode1 Ready worker1 27d v1.21.14 knode2 Ready worker2 27d v1.21.14 # 删除所有运行pod [root@kmaster pod]# kubectl scale deployment nginx --replicas=0 deployment.apps/nginx scaled # 重新设置nginx运行pod数量为4个副本 [root@kmaster pod]# kubectl scale deployment nginx --replicas=4 deployment.apps/nginx scaled # 再次查看pod分布情况,已经全部在knode2上了 [root@kmaster pod]# kubectl get pods -o wide --no-headers nginx-7cf7d6dbc8-hxzxn 1/1 Running 0 8s 10.244.69.193 knode2 <none> <none> nginx-7cf7d6dbc8-r5xxp 1/1 Running 0 8s 10.244.69.255 knode2 <none> <none> nginx-7cf7d6dbc8-r9p9b 1/1 Running 0 8s 10.244.69.194 knode2 <none> <none> nginx-7cf7d6dbc8-vqbnk 1/1 Running 0 8s 10.244.69.195 knode2 <none> <none>
如果需要pod在含有taint的节点上运行,则定义pod时需要指定toleration属性。
在pod定义toleration的格式如下:
tolerations: - key: "key值" operator: "Equal" value: "value值" effect: "值"
operator的值有一下两个:
Equal: value需要和taint的value值一样
Exists:可以不指定value值
设置operator的值为Equal # 为knode1设置标签,以便后续实验pod指定运行到knode1上 [root@kmaster pod]# kubectl label nodes knode1 diskxx=ssdxx node/knode1 labeled [root@kmaster pod]# kubectl apply -f podtaint.yaml pod/web1 created # 因为knode1设有污点,所以pod不能成功在knode1上创建 [root@kmaster pod]# kubectl get pods NAME READY STATUS RESTARTS AGE web1 0/1 Pending 0 5s # 设置pod的容忍污点属性 [root@kmaster pod]# cat podtaint.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: role: myrole name: web1 spec: nodeSelector: diskxx: ssdxx tolerations: # 设置容忍污点 - key: "keyxx" operator: "Equal" value: "valuexx" effect: "NoSchedule" containers: - image: nginx imagePullPolicy: IfNotPresent name: web1 resources: {} dnsPolicy: ClusterFirst restartPolicy: Always status: {} # 重新创建pod [root@kmaster pod]# kubectl apply -f podtaint.yaml pod/web1 created # pod已在knode1上正常运行 [root@kmaster pod]# kubectl get pod NAME READY STATUS RESTARTS AGE web1 1/1 Running 0 2s [root@kmaster pod]# kubectl delete -f podtaint.yaml pod "web1" deleted # 设置多个污点 [root@kmaster pod]# kubectl taint nodes knode1 key123=value123:NoSchedule node/knode1 tainted [root@kmaster pod]# kubectl apply -f podtaint.yaml pod/web1 created # 拉起失败,因为容忍污点需要匹配所有值 [root@kmaster pod]# kubectl get pods NAME READY STATUS RESTARTS AGE web1 0/1 Pending 0 6s [root@kmaster pod]# kubectl delete -f podtaint.yaml pod "web1" deleted # 要匹配所有的污点 [root@kmaster pod]# cat podtaint.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: role: myrole name: web1 spec: nodeSelector: diskxx: ssdxx tolerations: - key: "keyxx" # 第一个污点 operator: "Equal" value: "valuexx" effect: "NoSchedule" - key: "key123" # 第二个污点 operator: "Equal" value: "value123" effect: "NoSchedule" containers: - image: nginx imagePullPolicy: IfNotPresent name: web1 resources: {} [root@kmaster pod]# kubectl apply -f podtaint.yaml pod/web1 created [root@kmaster pod]# kubectl get pods NAME READY STATUS RESTARTS AGE web1 1/1 Running 0 3s # 清理 [root@kmaster pod]# kubectl delete -f podtaint.yaml pod "web1" deleted
设置operator的值为Exists 在设置节点taint的时候,如果value值为非空,tolerations字段只能写Equal不能写Exists。
# 使用exists参数则删除value值 [root@kmaster pod]# vim podtaint.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: role: myrole name: web1 spec: nodeSelector: diskxx: ssdxx tolerations: - key: "keyxx" operator: "Exists" # 同前对比 effect: "NoSchedule" - key: "key123" operator: "Exists" # 同前对比 effect: "NoSchedule" containers: - image: nginx imagePullPolicy: IfNotPresent name: web1 resources: {} [root@kmaster pod]# kubectl apply -f podtaint.yaml pod/web1 created [root@kmaster pod]# kubectl get pods NAME READY STATUS RESTARTS AGE web1 1/1 Running 0 3s # 清理 [root@kmaster pod]# kubectl delete -f podtaint.yaml pod "web1" deleted [root@kmaster pod]# kubectl taint node knode1 keyxx- node/knode1 untainted [root@kmaster pod]# kubectl taint node knode1 key123- node/knode1 untainted [root@kmaster pod]# kubectl describe nodes knode1 |grep -E '(Role|Taints)' Roles: worker1 Taints: <none>
存储管理 EmptyDir 部署kubens kubens 是一个切换kubectl切换命名空间的工具
[root@kmaster ~]# curl -L https://github.com/ahmetb/kubectx/releases/download/v0.9.1/kubens -o /usr/bin/kubens [root@kmaster ~]# chmod +x /usr/bin/kubens # 创建实验命名空间 [root@kmaster volume]# kubectl create ns nsvolume # 切换默认命名空间 [root@kmaster volume]# kubens nsvolume Context "kubernetes-admin@kubernetes" modified. Active namespace is "nsvolume".
创建并挂载卷 [root@kmaster volume ] apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: demo name: demo spec: volumes: - name: volume1 emptyDir: {} - name: volume2 emptyDir: {} containers: - image: busybox name: demo1 imagePullPolicy: IfNotPresent command: ['sh' ,'-c' ,'sleep 5000' ] volumeMounts: - mountPath: /xx name: volume1 - image: busybox name: demo2 imagePullPolicy: IfNotPresent command: ['sh' ,'-c' ,'sleep 5000' ] volumeMounts: - mountPath: /xx name: volume1 dnsPolicy: ClusterFirst [root@kmaster volume ] pod/demo created [root@kmaster volume ] NAME READY STATUS RESTARTS AGE IP NODE demo 2 /2 Running 0 12s 10.244 .69 .196 knode2 [root@kmaster volume ] Volumes: volume1: Type: EmptyDir (a temporary directory that shares a pod's lifetime) [root@knode2 ~ ] ac0372c61e48 beae173ccac6 "sh -c 'sleep 5000'" 20a2e64b96ba beae173ccac6 "sh -c 'sleep 5000'" [root@knode2 ~ ] "Mounts": [ { "Type": "bind" , "Source": "/var/lib/kubelet/pods/2fa695d5-b09a-45b1-afda-60436cbb469a/volumes/kubernetes.io~empty-dir/volume1" , "Destination": "/xx" , "Mode": "" , "RW": true , [root@knode2 ~ ] "Mounts": [ { "Type": "bind" , "Source": "/var/lib/kubelet/pods/2fa695d5-b09a-45b1-afda-60436cbb469a/volumes/kubernetes.io~empty-dir/volume1" , "Destination": "/xx" , "Mode": "" , "RW": true , [root@kmaster volume ] [root@kmaster volume ] hosts [root@knode2 ~ ] hosts
HostPath hostPath是将宿主机的本地目录映射到容器之中,删除pod之后,数据仍然保留,如果挂载点不存在,则自动创建。
# 创建相应hostPath实验pod [root@kmaster volume]# cat host.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: demo name: demo spec: volumes: - name: volume1 hostPath: # 存储类型 path: /data # 宿主机目录 containers: - image: busybox name: demo1 imagePullPolicy: IfNotPresent command: ['sh','-c','sleep 5000'] volumeMounts: - mountPath: /xx # 挂载目录 name: volume1 - image: busybox name: demo2 imagePullPolicy: IfNotPresent command: ['sh','-c','sleep 5000'] volumeMounts: - mountPath: /xx name: volume1 dnsPolicy: ClusterFirst restartPolicy: Always status: {} [root@kmaster volume]# kubectl apply -f host.yaml pod/demo created # 复制文件到宿主机/data目录下 [root@knode2 ~]# cp /etc/hosts /data [root@kmaster volume]# kubectl exec demo -c demo1 -- ls /xx hosts [root@kmaster volume]# kubectl exec demo -c demo2 -- ls /xx hosts
NFS存储 首先在192.168.10.5服务器上创建nfs服务,并配置挂载点和权限
# 配置nfs挂载pod [root@kmaster volume]# cat nfs.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: nginx name: demo spec: volumes: - name: volume1 nfs: server: 192.168.10.5 # 指定NFS服务器所在地址 path: "/data/nfshare" # 指定挂载路径 containers: - image: busybox imagePullPolicy: IfNotPresent name: demo1 command: ['sh','-c','sleep 5000'] volumeMounts: - name: volume1 mountPath: /xx resources: {} # 创建pod [root@kmaster volume]# kubectl apply -f nfs.yaml pod/demo created [root@kmaster volume]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE demo 1/1 Running 0 9s 10.244.69.197 knode2 [root@kmaster volume]# kubectl cp /etc/hosts demo:/xx ┌──[root@infra]-[/data/nfshare 17:31:48] └─#ls hosts
持久性存储 NFS作为后端存储,用户需要自行配置NFS服务器,而且需要root用户。PersistentVolume(持久性卷,简称pv)与后端存储关联,不属于任何命名空间,全局可见。用户登陆到自己的命名空间之后,只要创建pvc(持久性卷声明)即可实现pvc和pv的自动绑定。一个pv只能和一个pvc绑定。
PersistentVolume # 创建pv所需要的yaml文件 [root@kmaster volume]# cat pv1.yaml apiVersion: v1 kind: PersistentVolume # 指定创建pv metadata: name: pv01 spec: capacity: storage: 5Gi # 指定存储容量 volumeMode: Filesystem accessModes: # 访问模式 - ReadWriteOnce # 单个节点读写,ReaOnlyMany多个节点只读,ReadWriteMany多个节点读写 persistentVolumeReclaimPolicy: Recycle nfs: # 存储类型 path: /data/pvshare # 挂载路径 server: 192.168.10.5 # 挂载目标 # 创建pv [root@kmaster volume]# kubectl apply -f pv1.yaml persistentvolume/pv01 created # 查看pv [root@kmaster volume]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS pv01 5Gi RWO Recycle Available # pv01属性 [root@kmaster volume]# kubectl describe pv pv01 Name: pv01 Labels: <none> Annotations: <none> Finalizers: [kubernetes.io/pv-protection] StorageClass: Status: Available Claim: Reclaim Policy: Recycle Access Modes: RWO VolumeMode: Filesystem Capacity: 5Gi Node Affinity: <none> Message: Source: Type: NFS (an NFS mount that lasts the lifetime of a pod) Server: 192.168.10.5 Path: /data/pvshare ReadOnly: false
PersisentVolumeClaim # 创建pvc [root@kmaster volume]# cat pvc1.yaml kind: PersistentVolumeClaim # 创建pvc apiVersion: v1 metadata: name: pvc01 spec: accessModes: - ReadWriteOnce # 与对应pv类型一致,否则无法正常创建 volumeMode: Filesystem resources: requests: storage: 5Gi # 存储容量 # 创建pvc [root@kmaster volume]# kubectl apply -f pvc1.yaml persistentvolumeclaim/pvc01 created # 创建成功,pvc01对应pv01 [root@kmaster volume]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE pvc01 Bound pv01 5Gi RWO 3s
在pv和pvc的访问模式相同的情况下,pvc的容量请求大于pv的容量值得情况下不可绑定,反之小于或者等于pv得容量则可以绑定。
storageClassName 在存在多个pvc,但只有一个pv的情况时,可以通过storageClassName的标签来定义pv和pvc的绑定关系。
p’v和pvc实践 # 利用前面创建的pv01和pvc01,创建nginx pod [root@kmaster volume]# cat pod-nginx.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: nginx1 name: nginx1 spec: volumes: - name: myv persistentVolumeClaim: # 声明使用pvc,pvc的名字时pvc01 claimName: pvc01 containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx volumeMounts: # 挂载点 - mountPath: '/mnt' name: myv resources: {}
pv回收策略 创建pv时设定的 persistentVolumeReclaimPolicy: Recycle 就是用来设定回收策略的,即删除pvc之后释放pv。其中有两种策略:
Recycle:删除pvc之后,生成一个pod回收空间、删除pv数据,然后pv状态由Released变为Available,可供后续pvc使用。
Retain:不会受数据,删除pvc之后,pv不可用,pv状态长期保持为Released,需要手动删除pv,然后重新创建,删除pv页不会删除实际数据。
动态卷供应 前述持久性存储需要手动创建pv,然后才能创建pvc,为了减少操作,可以使用storageClass来解决这个问题。管理员只要创建好storageClass就不用设置pv,用户创建pvc的时候,自动创建pv和pvc进行绑定。
工作流程 定义stoageClass需要包含一个分配器(provisioner),不同的分配器决定了动态创建什么样的后端存储。storageClass又两种分配器:
内置分配器:kubernetes.io/glusterfs kubernetes.io/cinder kubernetes.io/vsphere-volume kubernetes.io/rdb 等
外部分配器:hostpath.csi.k8s.io lvmplugin.csi.alibabacloud.com
管理员创建storageClass时通过.provisioner字段指定分配器,用户在定义pvc时需要通过.spec.storageClassName指定使用那个storageClass。
利用nfs创建动态卷供应 # 在kubernetes中,NFS没有内置分配器,所以需要下载相关插件 [root@kmaster volume]# git clone https://github.com/kubernetes-incubator/external-storage.git [root@kmaster volume]# cd external-storage/nfs-client/deploy/ # 将默认命名空间default更换为实验使用nsvolume,然后部署rdac [root@kmaster volume]# sed -i 's/namespace: default/namespace: nsvolume/g' rbac.yaml # 创建相关权限设置 [root@kmaster deploy]# kubectl apply -f rbac.yaml
部署NFS分配器 # 修改NFS分配器部署 apiVersion: apps/v1 kind: Deployment metadata: name: nfs-client-provisioner labels: app: nfs-client-provisioner # replace with namespace where provisioner is deployed namespace: nsvolume # 修改默认default命名空间为nsvolume spec: replicas: 1 strategy: type: Recreate selector: matchLabels: app: nfs-client-provisioner template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: quay.io/external_storage/nfs-client-provisioner:latest # 镜像需要提前下载 volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: fuseim.pri/ifs # 分配器的名称 - name: NFS_SERVER value: 192.168.10.5 # NFS服务器的地址 - name: NFS_PATH value: /data/nfshare # 挂载目标 volumes: - name: nfs-client-root nfs: server: 192.168.10.5 # 挂载目标 path: /data/nfshare # 挂载路径 [root@kmaster deploy]# kubectl apply -f deployment.yaml [root@kmaster deploy]# kubectl get pod NAME READY STATUS RESTARTS AGE nfs-client-provisioner-79bb64c666-h6kcn 1/1 Running 6 16d
部署storageClass # 创建storageClass [root@kmaster deploy]# cat class.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: managed-nfs-storage provisioner: fuseim.pri/ifs # or choose another name, must match deployment's env PROVISIONER_NAME' parameters: archiveOnDelete: "false" # 部署并查看sc [root@kmaster deploy]# kubectl apply -f class.yaml [root@kmaster deploy]# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE managed-nfs-storage fuseim.pri/ifs Delete Immediate false 16d # 创建PVC [root@kmaster volume]# cat pvc1.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: pvc1 spec: accessModes: - ReadWriteOnce volumeMode: Filesystem resources: requests: storage: 1Mi storageClassName: managed-nfs-storage # 指定storageClassName # 创建pvc [root@kmaster volume]# kubectl apply -f pvc1.yaml persistentvolumeclaim/pvc1 created [root@kmaster volume]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE pvc1 Bound pvc-40dbd764-4eca-463b-93d9-3a1212e51cdd 1Mi RWO managed-nfs-storage 4s # 查看自动创建的 [root@kmaster volume]# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM pvc-40dbd764-4eca-463b-93d9-3a1212e51cdd 1Mi RWO Delete Bound nssec/pvc1 # 查看PV属性 [root@kmaster volume]# kubectl describe pv pvc-40dbd764-4eca-463b-93d9-3a1212e51cdd Name: pvc-40dbd764-4eca-463b-93d9-3a1212e51cdd Labels: <none> Annotations: pv.kubernetes.io/provisioned-by: fuseim.pri/ifs Finalizers: [kubernetes.io/pv-protection] StorageClass: managed-nfs-storage Status: Bound Claim: nssec/pvc1 Reclaim Policy: Delete Access Modes: RWO VolumeMode: Filesystem Capacity: 1Mi Node Affinity: <none> Message: Source: Type: NFS (an NFS mount that lasts the lifetime of a pod) Server: 192.168.10.5 Path: /data/nfshare/nssec-pvc1-pvc-40dbd764-4eca-463b-93d9-3a1212e51cdd ReadOnly: false Events: <none>
密码管理 使用yaml创建pod时,配置在yaml中env的密码,可以通过kubectl describe pod podname来发现,所以就需要使用secret和configmap来存储密码。
Secret secret的主要作用时存储密码信息,以及往pod中传递文件,以键值对的方式存储。
# 创建命名空间nssec并切换 [root@kmaster secret]# kubectl create ns nssec [root@kmaster secret]# kubens nssec Context "kubernetes-admin@kubernetes" modified. Active namespace is "nssec" # 查看当前secrets [root@kmaster secret]# kubectl get secrets NAME TYPE DATA AGE default-token-q4xqv kubernetes.io/service-account-token 3 15d
创建secret secret有三种类型:
Opaque: base64编码格式,用于存储密码、密钥,加密性弱
kuberenetes.io/dockerconfigjson: 用来存储私有docker registry的认证信息
kuberenetes.io/service-account-token: 用于被serviceaccount引用
命令行的方式 # 创建一个名字为mysecret1的secret,变量为xx=tom yy=redhat [root@kmaster secret]# kubectl create secret generic mysecret1 --from-literal=xx=tom --from-literal=yy=redhat # 查看当前secret [root@kmaster secret]# kubectl get secrets NAME TYPE DATA AGE default-token-q4xqv kubernetes.io/service-account-token 3 15d mysecret1 Opaque 2 15d [root@kmaster secret]# kubectl describe secrets mysecret1 Name: mysecret1 Namespace: nssec Labels: <none> Annotations: <none> Type: Opaque Data ==== xx: 3 bytes yy: 6 bytes # 查看mysecret键值对 [root@kmaster secret]# kubectl get secrets mysecret1 -o yaml apiVersion: v1 data: xx: dG9t # 键值经过base64加密 yy: cmVkaGF0 kind: Secret metadata: creationTimestamp: "2023-09-06T09:23:28Z" name: mysecret1 namespace: nssec resourceVersion: "159425" selfLink: /api/v1/namespaces/nssec/secrets/mysecret1 uid: c17dc6d6-be29-4d8b-89e0-70711e606496 type: Opaque # 进行base64 解密 [root@kmaster secret]# echo "dG9t" |base64 --decode tom [root@kmaster secret]# echo "vmVkaGF0" |base64 --decode redhat
文件的方式 这种方式的作用时把一个文件的内容写入secret中,后面通过卷的方式来引用这个secret,就可以把文件写入pod。
[root@kmaster secret]# kubectl create secret generic mysecret2 --from-file=/etc/hosts [root@kmaster secret]# kubectl get secrets mysecret2 -o yaml apiVersion: v1 data: hosts: MTI3LjAuMC4xICAgbG9jYWxob3N0IGxvY2FsaG9zdC5sb2NhbGRvbWFpbiBsb2NhbGhvc3Q0IGxvY2FsaG9zdDQubG9jYWxkb21haW40Cjo6MSAgICAgICAgIGxvY2FsaG9zdCBsb2NhbGhvc3QubG9jYWxkb21haW4gbG9jYWxob3N0NiBsb2NhbGhvc3Q2LmxvY2FsZG9tYWluNgoxOTIuMTY4LjEwLjEwCWttYXN0ZXIKMTkyLjE2OC4xMC4xMQlrbm9kZTEKMTkyLjE2OC4xMC4xMglrbm9kZTIK kind: Secret metadata: creationTimestamp: "2023-09-06T09:26:49Z" name: mysecret2 namespace: nssec resourceVersion: "159807" selfLink: /api/v1/namespaces/nssec/secrets/mysecret2 uid: e2046e54-6850-4a92-8373-df089a78d480 type: Opaque [root@kmaster secret]# echo "MTI3LjAuMC4xICAgbG9jYWxob3N0IGxvY2FsaG9zdC5sb2NhbGRvbWFpbiBsb2NhbGhvc3Q0IGxvY2FsaG9zdDQubG9jYWxkb21haW40Cjo6MSAgICAgICAgIGxvY2FsaG9zdCBsb2NhbGhvc3QubG9jYWxkb21haW4gbG9jYWxob3N0NiBsb2NhbGhvc3Q2LmxvY2FsZG9tYWluNgoxOTIuMTY4LjEwLjEwCWttYXN0ZXIKMTkyLjE2OC4xMC4xMQlrbm9kZTEKMTkyLjE2OC4xMC4xMglrbm9kZTIK" |base64 --decode 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.10 kmaster 192.168.10.11 knode1 192.168.10.12 knode2
变量文件的方式 [root@kmaster secret]# cat env.txt xx=tom yy=redhat [root@kmaster secret]# kubectl create secret generic mysecret4 --from-env-file=env.txt secret/mysecret4 created [root@kmaster secret]# kubectl describe secrets mysecret4 Name: mysecret4 Namespace: nssec Labels: <none> Annotations: <none> Type: Opaque Data ==== xx: 3 bytes yy: 6 bytes
yaml文件的方式 # 需要先得到键值的base64 编码之后的值 [root@kmaster secret]# echo -n 'tom' |base64 dG9t [root@kmaster secret]# echo -n 'redhat' |base64 cmVkaGF0 # 创建yaml文件 [root@kmaster secret]# cat secret5.yaml apiVersion: v1 kind: Secret metadata: name: mysecret5 type: Opaque data: xx: dG9t yy: cmVkaGF0 # 创建secret [root@kmaster secret]# kubectl apply -f secret5.yaml secret/mysecret5 created # 删除secrets [root@kmaster secret]# kubectl delete -f secret5.yaml secret "mysecret5" deleted [root@kmaster secret]# kubectl delete secrets mysecret4 secret "mysecret4" deleted
使用secret 以卷的方式 # 创建pod1,然后以卷的方式把mysecret2挂载到容器的/etc/test目录中 [root@kmaster secret]# cat pod1.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pod1 name: pod1 spec: volumes: - name: xx secret: secretName: mysecret2 containers: - image: nginx imagePullPolicy: IfNotPresent name: pod1 volumeMounts: - name: xx mountPath: "/etc/test" resources: {} # 创建pod [root@kmaster secret]# kubectl apply -f pod1.yaml pod/pod1 created [root@kmaster secret]# kubectl get pods NAME READY STATUS RESTARTS AGE pod1 1/1 Running 0 17s # 查看pod中的内容 [root@kmaster secret]# kubectl exec pod1 -- ls /etc/test hosts [root@kmaster secret]# kubectl exec pod1 -- cat /etc/test/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.10 kmaster 192.168.10.11 knode1 192.168.10.12 knode2
以变量的方式 在定义pod的yaml时,如果想要定义变量需要使用env配置name和value。使用secret则使用vauleFrom来引用变量。
# 创建一个数据库pod,使用yy这个键值对应的值redhat为管理员密码 [root@kmaster secret]# cat pod2.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pod2 name: pod2 spec: containers: - image: mariadb imagePullPolicy: IfNotPresent name: pod2 resources: {} env: - name: MYSQL_ROOT_PASSWORD valueFrom: # 应用secret的变量 secretKeyRef: name: mysecret1 key: yy # 创建pod [root@kmaster secret]# kubectl apply -f pod2.yaml pod/pod2 created # 获取IP [root@kmaster secret]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod1 1/1 Running 0 5m59s 10.244.69.199 knode2 <none> <none> # 连接数据库 [root@kmaster secret]# mysql -uroot -predhat -h10.224.69.203 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 4 Server version: 10.6.5-MariaDB-1:10.6.5+maria~focal mariadb.org binary distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+
Configmap configmap(简称为cm)作用与secret一样,主要作用时存储密码或者传递文件,也同样时键值对存储数据。它俩的主要区别在于secret使用base64进行编码,而confimap不需要。
创建confimap 命令行的方式 # 创建configmap my1 [root@kmaster secret]# kubectl create configmap my1 --from-literal=xx=tom --from-literal=yy=redhat configmap/my1 created # 查看my1,可见键值未被加密 [root@kmaster secret]# kubectl describe cm my1 Name: my1 Namespace: nssec Labels: <none> Annotations: <none> Data ==== xx: ---- tom yy: ---- redhat
创建文件的方式 [root@kmaster secret]# kubectl create configmap my2 --from-file=/etc/hosts --from-file=/etc/issue [root@kmaster secret]# kubectl describe cm my2 Name: my2 Namespace: nssec Labels: <none> Annotations: <none> Data ==== hosts: ---- 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.10 kmaster 192.168.10.11 knode1 192.168.10.12 knode2 issue: ---- \S Kernel \r on an \m
使用configmap 以卷的方式 # 创建pod3,将my2挂载到/etc/test路径下 [root@kmaster secret]# cat pod3.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pod3 name: pod3 spec: volumes: - name: xx configMap: name: my2 containers: - image: nginx imagePullPolicy: IfNotPresent name: pod3 resources: {} volumeMounts: - name: xx mountPath: "/etc/test" dnsPolicy: ClusterFirst [root@kmaster secret]# kubectl apply -f pod3.yaml pod/pod3 created # 查看文件复制 [root@kmaster secret]# kubectl exec pod3 -- ls /etc/test hosts issue [root@kmaster secret]# kubectl exec pod3 -- cat /etc/test/issue \S Kernel \r on an \m
以变量的方式 [root@kmaster secret]# cat pod4.yam apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: pod4 name: pod4 spec: containers: - image: idyci/mysql imagePullPolicy: IfNotPresent name: pod4 resources: {} env: - name: MYSQL_ROOT_PASSWORD valueFrom: # 表明变量引用 configMapKeyRef: # 从configMap中引用 name: my1 key: yy [root@kmaster secret]# kubectl apply -f pod4.yaml pod/pod4 configured # 获取节点信息和IP [root@kmaster secret]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE pod4 1/1 Running 0 8s 10.244.69.207 knode2 [root@knode2 ~]# docker exec -it 7e2b8691b89e bash root@pod4:/# mysql -uroot -predhat -h127.0.0.1 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.25 MySQL Community Server (GPL) Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec) mysql>
Deployment deployment(简称为deploy)是一个控制器,用来实现pod的多副本,从而保证pod的健壮性。
创建和删除deployment 使用yaml创建 # 创建实验用命名空间 [root@kmaster deploy]# kubectl create ns nsdeploy namespace/nsdeploy created [root@kmaster deploy]# kubens nsdeploy Context "kubernetes-admin@kubernetes" modified. Active namespace is "nsdeploy". # 使用命令行生成deployment的yaml文件 [root@kmaster deploy]# kubectl create deployment nginx --image=nginx --dry-run=client -o yaml > d1.yaml [root@kmaster deploy]# cat d1.yaml apiVersion: apps/v1 kind: Deployment # 创建类型为deployment metadata: creationTimestamp: null labels: app: nginx name: nginx spec: replicas: 3 # 副本数 selector: matchLabels: app: nginx strategy: {} template: metadata: creationTimestamp: null labels: app: nginx spec: containers: - image: nginx name: nginx imagePullPolicy: IfNotPresent resources: # 设置CPU资源限制 requests: cpu: 400m status: {} # 创建pod [root@kmaster deploy]# kubectl apply -f d1.yaml deployment.apps/nginx created [root@kmaster deploy]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-8lwfq 1/1 Running 0 11s 10.244.69.201 knode2 <none> <none> nginx-7cf7d6dbc8-hsm4p 1/1 Running 0 11s 10.244.195.154 knode1 <none> <none> nginx-7cf7d6dbc8-mk8cb 1/1 Running 0 11s 10.244.69.208 knode2 <none> <none> # 删除三个之一的pod [root@kmaster deploy]# kubectl delete pod nginx-7cf7d6dbc8-8lwfq pod "nginx-7cf7d6dbc8-8lwfq" deleted # 经观察,deployment会自动给再创建一个pod [root@kmaster deploy]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-hsm4p 1/1 Running 0 53s 10.244.195.154 knode1 <none> <none> nginx-7cf7d6dbc8-mk8cb 1/1 Running 0 53s 10.244.69.208 knode2 <none> <none> nginx-7cf7d6dbc8-svsnx 1/1 Running 0 6s 10.244.69.202 knode2 <none> <none>
健壮性测试 # 将knode1关机,然后观察pod运行情况 # 可见knode1已经下线 [root@kmaster deploy]# kubectl get nodes NAME STATUS ROLES AGE VERSION kmaster Ready control-plane,master 28d v1.21.14 knode1 NotReady worker1 28d v1.21.14 knode2 Ready worker2 28d v1.21.14 # 原有pod被中止,在可用节点上再拉起一个pod [root@kmaster deploy]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7cf7d6dbc8-hsm4p 1/1 Terminating 1 10m 10.244.195.156 knode1 <none> <none> nginx-7cf7d6dbc8-jmzzm 1/1 Running 0 44s 10.244.69.212 knode2 <none> <none> nginx-7cf7d6dbc8-mk8cb 1/1 Running 1 10m 10.244.69.209 knode2 <none> <none> nginx-7cf7d6dbc8-svsnx 1/1 Running 1 9m23s 10.244.69.214 knode2 <none> <none> # knode1上线 [root@kmaster deploy]# kubectl get nodes NAME STATUS ROLES AGE VERSION kmaster Ready control-plane,master 28d v1.21.14 knode1 Ready worker1 28d v1.21.14 knode2 Ready worker2 28d v1.21.14 # 原有knode1上被中止的pod已经删除,在knode2上的pod保留 [root@kmaster deploy]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE nginx-7cf7d6dbc8-jmzzm 1/1 Running 0 3m4s 10.244.69.212 knode2 nginx-7cf7d6dbc8-mk8cb 1/1 Running 1 12m 10.244.69.209 knode2 nginx-7cf7d6dbc8-svsnx 1/1 Running 1 11m 10.244.69.214 knode2 # 删除当前测试pod [root@kmaster deploy]# kubectl delete -f d1.yaml deployment.apps "nginx" deleted
修改副本数 通过命令行修改 # 利用前述d1.yaml文件创建一个nginx的deployment,副本数为3 [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-7cf7d6dbc8-94gc9 1/1 Running 0 59s nginx-7cf7d6dbc8-gzp8q 1/1 Running 0 59s nginx-7cf7d6dbc8-w997g 1/1 Running 0 59s # 将副本数修改为5 [root@kmaster deploy]# kubectl scale deployment nginx --replicas=5 deployment.apps/nginx scaled [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-7cf7d6dbc8-8lt4j 1/1 Running 0 2s nginx-7cf7d6dbc8-94gc9 1/1 Running 0 90s nginx-7cf7d6dbc8-gzp8q 1/1 Running 0 90s nginx-7cf7d6dbc8-nmhnd 1/1 Running 0 2s nginx-7cf7d6dbc8-w997g 1/1 Running 0 90s # 查看deployment信息 [root@kmaster deploy]# kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx 5/5 5 5 117s
编辑deployment修改 # 通过kubectl edit命令在线修改deployment的配置 [root@kmaster deploy]# kubectl edit deployments.apps nginx spec: progressDeadlineSeconds: 600 replicas: 2 revisionHistoryLimit: 10 selector: matchLabels: app: nginx # 保存退出 deployment.apps/nginx edited [root@kmaster deploy]# kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx 2/2 2 2 4m34s [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-7cf7d6dbc8-94gc9 1/1 Running 0 4m39s nginx-7cf7d6dbc8-nmhnd 1/1 Running 0 3m11s
修改yaml文件的方式 # 直接修改deployment的yaml文件,再不删除原有deploy的情况下再次导入生效 # 将副本数修改为4 [root@kmaster deploy]# vim d1.yaml [root@kmaster deploy]# kubectl get pods [root@kmaster deploy]# kubectl apply -f d1.yaml deployment.apps/nginx configured [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-7cf7d6dbc8-94gc9 1/1 Running 0 7m32s nginx-7cf7d6dbc8-ng8jg 1/1 Running 0 3s nginx-7cf7d6dbc8-nmhnd 1/1 Running 0 6m4s nginx-7cf7d6dbc8-xfb9r 1/1 Running 0 3s [root@kmaster deploy]# kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx 4/4 4 4 7m37s
水平自动更新HPA 水平自动跟新(Horizontal Pod Autosclers,HPA),可以通过检测pod的CPU负载通知deployment,让其自动增加或者减少pod数目。
配置HPA # 检查当前HPA配置情况 [root@kmaster deploy]# kubectl get hpa No resources found in nsdeploy namespace. # 检查当前deploy情况,可见nginx有4个pod运行 [root@kmaster deploy]# kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx 4/4 4 4 18m # 设置HPA为最小1个,最多3个 [root@kmaster deploy]# kubectl autoscale deployment nginx --min=1 --max=3 horizontalpodautoscaler.autoscaling/nginx autoscaled # deployment开始收缩 [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-7cf7d6dbc8-94gc9 1/1 Running 0 20m nginx-7cf7d6dbc8-ng8jg 1/1 Running 0 12m nginx-7cf7d6dbc8-nmhnd 1/1 Running 0 18m nginx-7cf7d6dbc8-xfb9r 0/1 Terminating 0 12m # 收缩完成 [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-7cf7d6dbc8-94gc9 1/1 Running 0 20m nginx-7cf7d6dbc8-ng8jg 1/1 Running 0 12m nginx-7cf7d6dbc8-nmhnd 1/1 Running 0 18m # 手动将deploy副本设为1 [root@kmaster deploy]# kubectl scale deployment nginx --replicas=1 deployment.apps/nginx scaled # 删除原有HPA [root@kmaster deploy]# kubectl delete hpa nginx horizontalpodautoscaler.autoscaling "nginx" deleted # 建立新的HPA,设为最小为1副本,最大为6副本,并设置CPU的阈值为70% [root@kmaster deploy]# kubectl autoscale deployment nginx --min=1 --max=6 --cpu-percent=70 horizontalpodautoscaler.autoscaling/nginx autoscaled [root@kmaster deploy]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE nginx Deployment/nginx 0%/70% 1 6 3 38s [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-6f9bcc8495-4nr8z 1/1 Running 0 4m26s nginx-6f9bcc8495-q7vdt 1/1 Running 0 4m26s nginx-6f9bcc8495-xr4hd 1/1 Running 0 4m26s
测试HPA # 手动将上述环境pod减少到一个 [root@kmaster deploy]# kubectl scale deployment nginx --replicas=1 deployment.apps/nginx scaled [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-6f9bcc8495-4nr8z 1/1 Running 0 5m35s # 创建对外的服务,端口80 [root@kmaster deploy]# kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort service/nginx exposed [root@kmaster deploy]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx NodePort 10.96.16.133 <none> 80:32030/TCP 6s # 其他主机通过访问192.168.10.10:32030端口就可以访问内部pod的nginx服务了 ──[root@infra]-[~ 19:02:26] └─#curl http://192.168.10.10:32030 <!DOCTYPE html> <html> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> </html> # 安装ab进行测试 ┌──[root@infra]-[~ 19:02:30] └─#yum install httpd-tools -y ┌──[root@infra]-[~ 19:04:17] └─#ab -t 600 -n 1000000 -c 1000 http://192.168.10.10:32030/index.html This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking 192.168.10.10 (be patient) # 可以看到nginx压力超过了cpu限制的70% [root@kmaster deploy]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE nginx Deployment/nginx 174%/70% 1 6 1 10m # HPA开始自动扩展,由一个pod扩展到3个,CPU压力下降到80% [root@kmaster deploy]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE nginx Deployment/nginx 81%/70% 1 6 3 11m # 最终达到CPU限制阈值,pod数为4个,CPU压力值下降到63%,HPA停止扩展 [root@kmaster deploy]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE nginx Deployment/nginx 63%/70% 1 6 4 12m # 停止AB测试,5分钟后pod收缩到1个 [root@kmaster deploy]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE nginx Deployment/nginx 0%/70% 1 6 1 25m [root@kmaster deploy]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-6f9bcc8495-hz2h9 1/1 Running 0 22m
镜像升级及回滚 # 将当前容器镜像设置为nginx 1.7.9 [root@kmaster deploy]# kubectl set image deployment/nginx nginx=1.7.9 deployment.apps/nginx image updated # 查看容器镜像版本升级纪录为空,需要--record参数 [root@kmaster deploy]# kubectl rollout history deployment nginx deployment.apps/nginx REVISION CHANGE-CAUSE 1 <none> 2 <none> # 将当前容器镜像设置为nginx latest版本 [root@kmaster deploy]# kubectl set image deployment/nginx nginx=nginx --record deployment.apps/nginx image updated [root@kmaster deploy]# kubectl rollout history deployment nginx deployment.apps/nginx REVISION CHANGE-CAUSE 2 <none> 3 kubectl set image deployment/nginx nginx=nginx --record=true # [root@kmaster deploy]# kubectl set image deployment/nginx nginx=1.9 --record deployment.apps/nginx image updated # 将当前容器镜像设置为nginx 1.24.0 [root@kmaster deploy]# kubectl set image deployment/nginx nginx=1.24.0 --record deployment.apps/nginx image updated # 查看容器镜像版本变化 [root@kmaster deploy]# kubectl rollout history deployment nginx deployment.apps/nginx REVISION CHANGE-CAUSE 2 <none> 3 kubectl set image deployment/nginx nginx=nginx --record=true 4 kubectl set image deployment/nginx nginx=1.9 --record=true 5 kubectl set image deployment/nginx nginx=1.24.0 --record=true # 查看当前容器镜像版本 [root@kmaster deploy]# kubectl get deployments.apps nginx -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR nginx 1/1 1 1 36m nginx 1.24.0 app=nginx # 对容器镜像进行回滚到操作纪录第四条 [root@kmaster deploy]# kubectl rollout undo deployment/nginx --to-revision=4 deployment.apps/nginx rolled back [root@kmaster deploy]# kubectl rollout history deployment nginx # 容器镜像版本回退到1.9 [root@kmaster deploy]# kubectl get deployments.apps nginx -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR nginx 1/1 1 1 40m nginx 1.9 app=nginx # 以上操作是对deployment部署pod进行删除然后全部按新版本镜像重新部署 # 滚动升级则需要先更新诺干pod,然后再进行下一步升级 # 重新配置deployment的yaml文件 [root@kmaster deploy]# cat d1.yaml apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: nginx name: nginx spec: replicas: 5 selector: matchLabels: app: nginx strategy: # 新增滚动升级属性 rollingUpdate: maxSurge: 1 # 最多一次创建几个pod,也可以是百分比 maxUnavailable: 1 #最多一次删除几个pod,也可以是百分比 template: metadata: creationTimestamp: null labels: app: nginx spec: containers: - image: nginx:1.7.9 name: nginx imagePullPolicy: IfNotPresent resources: requests: cpu: 400m status: {} # 删除原有HPA [root@kmaster deploy]# kubectl delete hpa nginx horizontalpodautoscaler.autoscaling "nginx" deleted [root@kmaster deploy]# kubectl delete -f d1.yaml deployment.apps "nginx" deleted # 重新读取deployment的yaml文件 [root@kmaster deploy]# kubectl apply -f d1.yaml deployment.apps/nginx configured [root@kmaster deploy]# kubectl get deploy -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR nginx 5/5 5 5 26s nginx nginx:1.7.9 app=nginx # 升级镜像版本为1.9 [root@kmaster deploy]# kubectl set image deployment/nginx nginx=nginx deployment.apps/nginx image updated # 开始进行升级替换 [root@kmaster deploy]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE nginx-6dffbbc64-drkmw 1/1 Running 0 16s 10.244.195.191 knode1 nginx-6dffbbc64-hjrvg 1/1 Running 0 10s 10.244.69.246 knode2 nginx-6dffbbc64-rw4b9 1/1 Running 0 14s 10.244.195.129 knode1 nginx-6dffbbc64-wv4jd 0/1 ContainerCreating 0 9s <none> knode1 nginx-6dffbbc64-xhdgl 1/1 Running 0 16s 10.244.69.242 knode2 # 升级完毕 [root@kmaster deploy]# kubectl get deploy -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR nginx 5/5 5 5 4m35s nginx nginx app=nginx
Daemonset控制器 daemonset是和deployment类似的控制器,但daemonset会在所有的节点上都创建一个pod,有几个节点就创建几个pod,每个节点只有一个pod。主要用于监控、日志等。
创建及删除ds # 设置实验环境 [root@kmaster ~]# mkdir daemonset [root@kmaster ~]# cd daemonset/ [root@kmaster daemonset]# kubectl create ns nsds namespace/nsds created [root@kmaster daemonset]# kubens nsds Context "kubernetes-admin@kubernetes" modified. Active namespace is "nsds". # 创建ds的yaml文件 [root@kmaster daemonset]# cat ds1.yaml apiVersion: apps/v1 kind: DaemonSet metadata: creationTimestamp: null labels: app: ds1 name: ds1 spec: selector: matchLabels: app: busybox template: metadata: labels: app: busybox spec: containers: - command: - sh - -c - sleep 3600 image: busybox imagePullPolicy: IfNotPresent name: busybox # 创建daemonSet [root@kmaster daemonset]# kubectl apply -f ds1.yaml daemonset.apps/ds1 created [root@kmaster daemonset]# kubectl get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE ds1 2 2 2 2 2 <none> 7s # 查看创建的pod,因为Master有污点,所有只在worker节点上运行 [root@kmaster daemonset]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ds1-s4qvb 1/1 Running 0 20s 10.244.195.138 knode1 <none> <none> ds1-tqjp6 1/1 Running 0 20s 10.244.69.244 knode2 <none> <none> # 删除daemonset [root@kmaster daemonset]# kubectl delete -f ds1.yaml daemonset.apps "ds1" deleted
探针 probe(探针)是定义在容器内,用来探测容器是否工作正常的,分为liveness probe和readiness proble.
liveness probe liveness探测到某个pod运行有问题的化,就把有问题的pod内的容器删除,然后在此pod中重新创建一个容器。
command探测方式 command探测方式就是在容器内部执行一条命令,如果返回值为0,则命令正确执行、容器时正常的,反之则删除容器并重建。以下实验为创建/tmp/healthy文件,在容器启动30秒时删除,然后每5秒检查一次,一共重复检查3次,第45秒时会重启,由于关闭pod有30秒宽限期,所以pod会在第75秒真正重启。
# 创建实验环境 [root@kmaster ~]# mkdir probe [root@kmaster ~]# cd probe/ [root@kmaster probe]# ls [root@kmaster probe]# kubectl create ns nsprobe namespace/nsprobe created [root@kmaster probe]# kubens nsprobe Context "kubernetes-admin@kubernetes" modified. Active namespace is "nsprobe". # 配置实验yaml文件 [root@kmaster probe]# cat livenss1.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: liveness name: liveness-exec namespace: nsprobe spec: containers: - name: liveness image: busybox imagePullPolicy: IfNotPresent args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 1000 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 5 periodSeconds: 5 # 创建探针 [root@kmaster probe]# kubectl apply -f livenss1.yaml pod/liveness-exec created [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 0 74s # pod重启一次 [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 1 90s # pod经过9分钟重启6次 [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 6 8m57s
livenss probe httpGet 探测方式 用HTTP协议的数据包通过指定的端口访问指定的文件,如果可以访问,则认为时正常的;反之,则是不正常的,需要重启pod。
# 配置探针 [root@kmaster probe]# cat livenss2.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: liveness name: liveness-http namespace: nsprobe spec: containers: - name: liveness image: nginx imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /index.html port: 80 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 5 successThreshold: 1 # 创建pod [root@kmaster probe]# kubectl apply -f livenss2.yaml pod/liveness-http created # pod创建成功 [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-http 1/1 Running 0 10m # 进入容器,删除index.html文件 [root@kmaster probe]# kubectl exec -it liveness-http -- bash root@liveness-http:/# rm -rf /usr/share/nginx/html/index.html root@liveness-http:/# exit exit # pod发生重启 [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-http 1/1 Running 1 11m
livenss probe tcpScoket 探测方式 tcpSocket的探测方式是指是否能和指定的端口建立tcp三次握手。
# 探针监测nginx的808端口,每隔5秒监测一次,三次失败之后重启pod [root@kmaster probe]# cat livenss3.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: liveness name: liveness-tcp namespace: nsprobe spec: containers: - name: liveness image: nginx imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 tcpSocket: port: 808 initialDelaySeconds: 5 periodSeconds: 5 # 创建容器 [root@kmaster probe]# kubectl apply -f livenss3.yaml pod/liveness-tcp created # 初始状态 [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-tcp 1/1 Running 0 6s # 监测不到808端口,则重启pod,时间间隔为15秒 [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-tcp 1/1 Running 1 21s
readiness probe readiness探针的探测方式和liveness类似,但后续处理不是重启pod,而是将请求不再转发给此pod。
# 创建三个pod,并在pod中创建文件/tmp/healthy文件,当探针监测到该文件存在时,pod为健康的,否则认为pod故障。 [root@kmaster probe]# cat pod1.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: app name: pod1 namespace: nsprobe spec: containers: - name: c1 image: nginx imagePullPolicy: IfNotPresent lifecycle: postStart: exec: command: ["/bin/sh","-c","touch /tmp/healthy"] readinessProbe: exec: command: ["cat","/tmp/healthy"] [root@kmaster probe]# kubectl apply -f pod1.yaml pod/pod1 created [root@kmaster probe]# sed 's/pod1/pod2/' pod1.yaml |kubectl apply -f - pod/pod2 created [root@kmaster probe]# sed 's/pod1/pod3/' pod1.yaml |kubectl apply -f - pod/pod3 created [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE pod1 1/1 Running 0 39s pod2 1/1 Running 0 10s pod3 1/1 Running 0 5s # 创建readsvc的svc,根据run=app标签,关联所有pod [root@kmaster probe]# kubectl expose --name=readsvc pod pod1 --port=80 --selector=run=app service/readsvc exposed # 分别标记不同的pod [root@kmaster probe]# kubectl exec -it pod1 -- bash root@pod1:/# echo 111 > /usr/share/nginx/html/index.html root@pod1:/# exit exit [root@kmaster probe]# kubectl exec -it pod2 -- bash root@pod2:/# echo 222 > /usr/share/nginx/html/index.html root@pod2:/# exit exit [root@kmaster probe]# kubectl exec -it pod3 -- bash root@pod3:/# echo 333 > /usr/share/nginx/html/index.html root@pod3:/# exit exit # 获取readsvc的ip [root@kmaster probe]# kubectl get svc readsvc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE readsvc ClusterIP 10.108.151.61 <none> 80/TCP 2m33s # 服务请求以轮询的方式发送到pod上 [root@kmaster probe]# curl -s 10.108.151.61 111 [root@kmaster probe]# curl -s 10.108.151.61 222 [root@kmaster probe]# curl -s 10.108.151.61 333 [root@kmaster probe]# curl -s 10.108.151.61 111 # 删除探针监测文件,让pod1探测失败 [root@kmaster probe]# kubectl exec -it pod1 -- bash root@pod1:/# rm /tmp/healthy root@pod1:/# ls /tmp/ root@pod1:/# exit exit [root@kmaster probe]# kubectl describe pod pod1 Name: pod1 Namespace: nsprobe Priority: 0 Node: knode2/192.168.10.12 Start Time: Mon, 25 Sep 2023 15:05:20 +0800 Labels: run=app Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 8m6s default-scheduler Successfully assigned nsprobe/pod1 to knode2 Normal Pulled 8m5s kubelet Container image "nginx" already present on machine Normal Created 8m5s kubelet Created container c1 Normal Started 8m5s kubelet Started container c1 Warning Unhealthy 6s (x3 over 26s) kubelet Readiness probe failed: cat: /tmp/healthy: No such file or directory # 监测pod运行状态,pod正常运行,但不是ready状态 [root@kmaster probe]# kubectl get pods NAME READY STATUS RESTARTS AGE pod1 0/1 Running 0 9m8s pod2 1/1 Running 0 8m39s pod3 1/1 Running 0 8m34s # pod1不再被轮询 [root@kmaster probe]# curl -s 10.108.151.61 333 [root@kmaster probe]# curl -s 10.108.151.61 222 [root@kmaster probe]# curl -s 10.108.151.61 333 [root@kmaster probe]# curl -s 10.108.151.61 222 # 清理环境 [root@kmaster probe]# kubectl delete svc readsvc service "readsvc" deleted [root@kmaster probe]# kubectl delete pod pod{1,2,3} --force warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "pod1" force deleted pod "pod2" force deleted pod "pod3" force deleted
Job job job用于一次性任务,一个job启动一个pod去完成一个任务,如果pod成功执行,则job结束;如果执行失败,则会重新创建一个pod再次执行。
# 准备实验环境 [root@kmaster ~]# mkdir job [root@kmaster ~]# cd job/ [root@kmaster job]# kubens nsjob Context "kubernetes-admin@kubernetes" modified. Active namespace is "nsjob".
创建job # 创建一个名为job1的job,使用busybox镜像,执行命令“hello”,然后休眠30秒 [root@kmaster job]# kubectl create job job1 --image=busybox --dry-run=client -o yaml -- sh -c "echo hello && sleep 30" > job1.yaml # 手动添加镜像下载策略为IfNotPresent # job的重启策略分为两种Never(只要任务没有完成则新建pod)和 OnFailure(只要pod没有完成,则重启pod) [root@kmaster job]# cat job1.yaml apiVersion: batch/v1 kind: Job metadata: creationTimestamp: null name: job1 spec: template: metadata: creationTimestamp: null spec: containers: - command: - sh - -c - echo hello && sleep 30 image: busybox imagePullPolicy: IfNotPresent name: job1 resources: {} restartPolicy: Never status: {} # 创建job [root@kmaster job]# kubectl apply -f job1.yaml job.batch/job1 created # 查看job执行情况,echo 的30秒没有完成,则显示未完成 [root@kmaster job]# kubectl get job NAME COMPLETIONS DURATION AGE job1 0/1 4s 4s # 30秒之后完成任务,job结束 [root@kmaster job]# kubectl get job NAME COMPLETIONS DURATION AGE job1 1/1 32s 2m39s # pod的描述为已完成 [root@kmaster job]# kubectl get pods NAME READY STATUS RESTARTS AGE job1-thrdn 0/1 Completed 0 3m6s # 清理 [root@kmaster job]# kubectl delete -f job1.yaml job.batch "job1" deleted
job添加参数 job的参数有:
parallelism:N 并行运行N个pod
completions: M 要M次成功才算成功,如果没有则要重复执行
backoffLimit: N 如果job失败,要重复几次
activeDeadlinSeconds: N job最长运行时间,单位时秒,超时则job被终止,pod也会被强制删除
# 利用前述job1.yaml文件,添加job参数 [root@kmaster job]# cat job2.yaml apiVersion: batch/v1 kind: Job metadata: creationTimestamp: null name: job2 spec: parallelism: 3 # 并发3个pod completions: 6 # 需要执行6次 backoffLimit: 4 # job失败重试4次 activeDeadlineSeconds: 60 # 60秒后结束 template: metadata: creationTimestamp: null spec: containers: - command: - sh - -c - echo hello && sleep 30 image: busybox imagePullPolicy: IfNotPresent name: job2 resources: {} restartPolicy: Never status: {} [root@kmaster job]# kubectl apply -f job2.yaml job.batch/job2 created # 开始执行job [root@kmaster job]# kubectl get jobs.batch NAME COMPLETIONS DURATION AGE job2 0/6 12s 13s [root@kmaster job]# kubectl get pods NAME READY STATUS RESTARTS AGE job2-9dgzs 0/1 ContainerCreating 0 2s job2-c46bz 0/1 ContainerCreating 0 1s job2-cwr6j 0/1 Completed 0 34s job2-fbdpz 0/1 ContainerCreating 0 1s job2-r4cvz 0/1 Completed 0 34s job2-rft22 0/1 Completed 0 34s # 完成任务 [root@kmaster job]# kubectl get jobs NAME COMPLETIONS DURATION AGE job2 6/6 24s 49s [root@kmaster job]# kubectl get pods NAME READY STATUS RESTARTS AGE job2-2tq8l 0/1 Completed 0 25s job2-8bfpl 0/1 Completed 0 13s job2-fr5ck 0/1 Completed 0 13s job2-h4t8q 0/1 Completed 0 25s job2-m9879 0/1 Completed 0 25s job2-p644j 0/1 Completed 0 13s # 将job2.yaml中的echo 修改为ehcoX,job任务执行失败 [root@kmaster job]# kubectl get pods NAME READY STATUS RESTARTS AGE job2-868pt 0/1 Error 0 16s job2-bstm5 0/1 Error 0 17s job2-fkctc 0/1 Error 0 19s job2-hkkls 0/1 Error 0 16s job2-m4r5c 0/1 Error 0 19s job2-zrsp2 0/1 Error 0 19s [root@kmaster job]# kubectl get jobs NAME COMPLETIONS DURATION AGE job2 0/6 23s 23s
cronjob cronjob时循环性的、周期性任务,简写为cj
# 创建cronjob的yaml文件 [root@kmaster job]# kubectl create cronjob job3 --image=busybox --namespace=nsjob --schedule="*/1 * * * *" --dry-run=client -o yaml -- /bin/sh -c "echo Hello World" > job3.yaml [root@kmaster job]# cat job3.yaml apiVersion: batch/v1 kind: CronJob metadata: creationTimestamp: null name: job3 namespace: nsjob spec: jobTemplate: metadata: creationTimestamp: null name: job3 spec: template: metadata: creationTimestamp: null spec: containers: - command: - /bin/sh - -c - echo Hello World image: busybox imagePullPolicy: IfNotPresent name: job3 resources: {} restartPolicy: OnFailure schedule: '*/1 * * * *' # 创建job [root@kmaster job]# kubectl apply -f job3.yaml cronjob.batch/job3 created # 查看执行情况 [root@kmaster job]# kubectl get cj NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE job3 */1 * * * * False 0 23s 25s [root@kmaster job]# kubectl get pods NAME READY STATUS RESTARTS AGE job3-28260494-qk765 0/1 Completed 0 2s # 一分钟以后 [root@kmaster job]# kubectl get jobs NAME COMPLETIONS DURATION AGE job3-28260494 1/1 1s 60s job3-28260495 0/1 0s 0s [root@kmaster job]# kubectl get pods NAME READY STATUS RESTARTS AGE job3-28260494-qk765 0/1 Completed 0 64s job3-28260495-6t925 0/1 Completed 0 4s # 两分钟以后 [root@kmaster job]# kubectl get jobs NAME COMPLETIONS DURATION AGE job3-28260494 1/1 1s 2m4s job3-28260495 1/1 1s 64s job3-28260496 1/1 1s 4s [root@kmaster job]# kubectl get pods NAME READY STATUS RESTARTS AGE job3-28260496-l9rrg 0/1 Completed 0 2m7s job3-28260497-4bgrv 0/1 Completed 0 67s job3-28260498-wdh8p 0/1 Completed 0 7s [root@kmaster job]# kubectl logs job3-28260498-wdh8p Hello World
服务管理 pod不是健壮的,可能会随时挂掉,配置deployment会重新生成pod,但新的pod的IP地址会发生变化,同时负载较大也无法实现负载均衡。可以把service理解为一个负载均衡器,所有发送给svc的请求,都会转发给后端的pod,pod越多,每个pod的负载就越低。service的转发功能是由kube-proxy组件来实现,定位功能是由标签(label)来实现。
基本管理 环境准备 [root@kmaster ~]# mkdir svc [root@kmaster ~]# kubectl create namespace nssvc namespace/nssvc created [root@kmaster svc]# kubens nssvc Context "kubernetes-admin@kubernetes" modified. Active namespace is "nssvc" [root@kmaster ~]# kubectl create deployment web --image=nginx --dry-run=client -o yaml > web.yaml [root@kmaster ~]# vim web.yaml [root@kmaster ~]# kubectl apply -f web.yaml deployment.apps/web created [root@kmaster svc]# kubectl get pods NAME READY STATUS RESTARTS AGE web-748964f56b-7c7rx 1/1 Running 0 123m [root@kmaster svc]# kubectl get deployments.apps -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR web 1/1 1 1 124m nginx nginx app1=web1
创建svc # 创建名为svc1的servcie,对外服务端口为80,指向pod的端口为80 [root@kmaster svc]# kubectl expose deployment web --name=svc1 --port=80 --target-port=80 service/svc1 exposed # 应对多个标签的pod,可以直接标注使用那个标签 [root@kmaster svc]# kubectl expose deployment web --name=svc1 --port=80 --target-port=80 --selector=app1=web1 # 查看service群集IP为10.105.121.187,端口为80 [root@kmaster svc]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc1 ClusterIP 10.105.121.187 <none> 80/TCP 70s # 查看svc属性,可见Endpoints,也就是后端IP为10.244.69.233:80 [root@kmaster svc]# kubectl describe svc svc1 Name: svc1 Namespace: nssvc Labels: app=web Annotations: <none> Selector: app1=web1 Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.105.121.187 IPs: 10.105.121.187 Port: <unset> 80/TCP TargetPort: 80/TCP Endpoints: 10.244.69.233:80 Session Affinity: None Events: <none> # endpoints对应的pod [root@kmaster svc]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-748964f56b-7c7rx 1/1 Running 0 127m 10.244.69.233 knode2 <none> <none> # 修改deployment副本数为3 [root@kmaster svc]# kubectl scale deployment web --replicas=3 deployment.apps/web scaled # 对应pod增加为3个 [root@kmaster svc]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-748964f56b-6ndsf 1/1 Running 0 5s 10.244.195.154 knode1 <none> <none> web-748964f56b-7c7rx 1/1 Running 0 130m 10.244.69.233 knode2 <none> <none> web-748964f56b-vxrr8 1/1 Running 0 5s 10.244.69.232 knode2 <none> <none> # 对应IP也增加为3个 [root@kmaster svc]# kubectl describe svc svc1 Name: svc1 Namespace: nssvc Labels: app=web Annotations: <none> Selector: app1=web1 # service根据app1=web1自动对应新增pod Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.105.121.187 IPs: 10.105.121.187 Port: <unset> 80/TCP TargetPort: 80/TCP Endpoints: 10.244.195.154:80,10.244.69.232:80,10.244.69.233:80 Session Affinity: None Events: <none> # 清理 [root@kmaster svc]# kubectl delete svc web1
使用yaml创建svc [root@kmaster svc]# kubectl expose deployment web --name=svc1 --port=80 --target-port=80 --selector=app1=web1 --dry-run=client -o yaml > svc1.yaml [root@kmaster svc]# cat svc1.yaml apiVersion: v1 kind: Service metadata: creationTimestamp: null labels: app: web name: svc1 spec: ports: - port: 80 protocol: TCP targetPort: 80 selector: app1: web1 status: loadBalancer: {} [root@kmaster svc]# kubectl apply -f svc1.yaml service/svc1 created [root@kmaster svc]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc1 ClusterIP 10.96.205.219 <none> 80/TCP 5s [root@kmaster svc]# kubectl get pods NAME READY STATUS RESTARTS AGE web-748964f56b-6ndsf 1/1 Running 0 8m8s web-748964f56b-7c7rx 1/1 Running 0 138m web-748964f56b-vxrr8 1/1 Running 0 8m8s [root@kmaster svc]# kubectl describe svc svc1 Name: svc1 Namespace: nssvc Labels: app=web Annotations: <none> Selector: app1=web1 Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.96.205.219 IPs: 10.96.205.219 Port: <unset> 80/TCP TargetPort: 80/TCP Endpoints: 10.244.195.154:80,10.244.69.232:80,10.244.69.233:80 Session Affinity: None Events: <none>
服务发现 多个pod联合使用的应用,比如wordpress+mysql构建blog站点,就需要wordpress的pod和mysql的pod进行通信,这就需要服务发现.
使用集群IP访问svc # 创建mysql的pod [root@kmaster svc]# cat pod-mysql.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: mysql name: mysql namespace: nssvc spec: containers: - image: mariadb imagePullPolicy: IfNotPresent name: mysql env: - name: MYSQL_ROOT_PASSWORD value: redhat - name: MYSQL_USER value: tom - name: MYSQL_PASSWORD value: redhat - name: MYSQL_DATABASE value: blog ports: - containerPort: 3306 name: mysql resources: {} dnsPolicy: ClusterFirst restartPolicy: Always status: {} [root@kmaster svc]# kubectl apply -f pod-mysql.yaml pod/mysql created [root@kmaster svc]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mysql 1/1 Running 0 34s 10.244.69.231 knode2 <none> <none> [root@kmaster svc]# mysql -utom -predhat -h10.244.69.231 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 3 Server version: 10.6.5-MariaDB-1:10.6.5+maria~focal mariadb.org binary distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]> show databases; +--------------------+ | Database | +--------------------+ | blog | | information_schema | +--------------------+ 2 rows in set (0.00 sec) # 创建mysql的service [root@kmaster svc]# kubectl expose pod mysql --name=dbsvc --port=3306 service/dbsvc exposed [root@kmaster svc]# kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR dbsvc ClusterIP 10.105.5.226 <none> 3306/TCP 11s run=mysql # 创建wordpress的pod [root@kmaster svc]# cat pod-wordpress.yaml apiVersion: v1 kind: Pod metadata: creationTimestamp: null labels: run: wordpress name: wordpress namespace: nssvc spec: containers: - image: wordpress imagePullPolicy: IfNotPresent name: wordpress env: # 环境变量指定wordpress连接数据库的用户和主机 - name: WORDPRESS_DB_USER value: root - name: WORDPRESS_DB_PASSWORD value: redhat - name: WORDPRESS_DB_NAME value: blog - name: WORDPRESS_DB_HOST value: 10.105.5.226 ports: - containerPort: 80 name: wordpress resources: {} dnsPolicy: ClusterFirst restartPolicy: Always status: {} [root@kmaster svc]# kubectl apply -f pod-wordpress.yaml [root@kmaster svc]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mysql 1/1 Running 0 9m4s 10.244.69.231 knode2 <none> <none> wordpress 1/1 Running 0 100s 10.244.195.157 knode1 <none> <none> [root@kmaster svc]# curl -i 10.244.195.157 HTTP/1.1 302 Found Date: Mon, 25 Sep 2023 12:46:54 GMT Server: Apache/2.4.51 (Debian) X-Powered-By: PHP/7.4.27 Expires: Wed, 11 Jan 1984 05:00:00 GMT Cache-Control: no-cache, must-revalidate, max-age=0 X-Redirect-By: WordPress Location: http://10.244.195.156/wp-admin/install.php Content-Length: 0 Content-Type: text/html; charset=UTF-8
通过变量的方式访问 通过变量方式访问,发起pod和访问pod必须在同一个命名空间,同时创建服务必须要有先后顺序.
# 查看wordpress自动学习的变量 [root@kmaster svc]# kubectl exec wordpress -it -- bash root@wordpress:/var/www/html# env |grep DBSVC DBSVC_PORT=tcp://10.105.5.226:3306 DBSVC_PORT_3306_TCP_ADDR=10.105.5.226 DBSVC_PORT_3306_TCP=tcp://10.105.5.226:3306 DBSVC_PORT_3306_TCP_PORT=3306 DBSVC_SERVICE_PORT=3306 DBSVC_SERVICE_HOST=10.105.5.226 DBSVC_PORT_3306_TCP_PROTO=tcp # 所以就可以将yaml中的键值替换 env: # 环境变量指定wordpress连接数据库的用户和主机 - name: WORDPRESS_DB_USER value: root - name: WORDPRESS_DB_PASSWORD value: redhat - name: WORDPRESS_DB_NAME value: blog - name: WORDPRESS_DB_HOST value: $(DBSVC_SERVICE_HOST)
通过DNS的方式访问 在kubernetes安装完成之后,在kube-system命名空间中有一个coredns的deployment,其前端为kube-dns的svc,其作用就是在整个集群中不管那个命名空间,只要创建了服务,都会在coreDNS中自动注册,这样coreDNS就会知道每个服务以及IP地址的对应关系.
[root@kmaster svc]# kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE coredns-59d64cd4d4-hpnvx 1/1 Running 16 32d coredns-59d64cd4d4-nbfxd 1/1 Running 3 3d2h [root@kmaster svc]# kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 32d # 创建临时pod访问dbsvc [root@kmaster svc]# kubectl run busybox --rm -it --image=busybox sh If you don't see a command prompt, try pressing enter. / # ping dbsvc PING dbsvc (10.105.5.226): 56 data bytes # 可见可以正常解析 # 所以就可以将yaml中的键值替换 env: # 环境变量指定wordpress连接数据库的用户和主机 - name: WORDPRESS_DB_USER value: root - name: WORDPRESS_DB_PASSWORD value: redhat - name: WORDPRESS_DB_NAME value: blog - name: WORDPRESS_DB_HOST value: dbsvc
服务发布 svc的IP只有集群内部主机以及pod才可以访问,如果需要外部访问则需要服务发布
NodePort # 已有mysql和wordpress的pod [root@kmaster svc]# kubectl get pods NAME READY STATUS RESTARTS AGE mysql 1/1 Running 0 37m wordpress 1/1 Running 0 9s # 将wordpress的80端口以NodePort的形式发布出去 [root@kmaster svc]# kubectl expose pod wordpress --name=blog --port=80 --type=NodePort service/blog exposed # 就可以以任一个节点的IP:31260访问wordpress [root@kmaster svc]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE blog NodePort 10.102.76.168 <none> 80:31260/TCP 5s dbsvc ClusterIP 10.105.5.226 <none> 3306/TCP 34m
LoadBalancer 如果通过loadbalancer的方式来发布服务的话,每个svc都会获取一个IP,所以需要部署一个地址池用于IP分配。此类服务需要第三方工具Metallb 。
# 环境准备 [root@kmaster ~]# kubectl create ns metallb-system namespace/metallb-system created # 下载部署yaml文件 [root@kmaster ~]# wget https://raw.githubusercontent.com/metallb/metallb/v0.13.11/config/manifests/metallb-native.yaml # 在各个节点上准备镜像 [root@knode1 ~]# docker pull quay.io/metallb/controller:v0.13.11 [root@knode1 ~]# docker pull quay.io/metallb/speaker:v0.13.11 # 编辑metallb-native.yaml,添加镜像下载属性 IfNotPresent [root@kmaster ~]# kubectl apply -f metallb-native.yaml # 部署完成 [root@kmaster ~]# kubectl get pods -n metallb-system NAME READY STATUS RESTARTS AGE controller-567c78c4c-59ntw 1/1 Running 1 14m speaker-fp7n4 1/1 Running 0 14m speaker-sf5dn 1/1 Running 0 14m speaker-vq8pd 1/1 Running 0 14m # 创建IP地址池的声明,使用192.168.10.150/30网段作为映射IP [root@kmaster svc]# cat ip-pool.yaml apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: ip-pool namespace: metallb-system spec: addresses: - 192.168.10.150/30 # 创建Layer2的网络,调用ip-pool的IP地址池 [root@kmaster svc]# cat advertise.yaml apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2adver namespace: metallb-system spec: ipAddressPools: - ip-pool # 创建IP地址池 [root@kmaster svc]# kubectl apply -f ip-pool.yaml ipaddresspool.metallb.io/ip-pool created # 创建IP地址调用 [root@kmaster svc]# kubectl apply -f advertise.yaml l2advertisement.metallb.io/l2adver created # 创建一个临时的nginx pod [root@kmaster svc]# kubectl run pod1 --image=nginx --image-pull-policy=IfNotPresent pod/pod1 created # 创建一个测试svc [root@kmaster svc]# kubectl expose --name=svc1 pod pod1 --port=80 --type=LoadBalancer service/svc1 exposed # 可见指定的IP地址池的IP被映射为访问IP [root@kmaster svc]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc1 LoadBalancer 10.109.84.61 192.168.10.148 80:32605/TCP 10m [root@kmaster svc]# curl 192.168.10.148 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> </body> </html> # 清理 [root@kmaster svc]# kubectl delete -f advertise.yaml l2advertisement.metallb.io "l2adver" deleted [root@kmaster svc]# kubectl delete -f ip-pool.yaml ipaddresspool.metallb.io "ip-pool" deleted [root@kmaster svc]# kubectl delete -f metallb-native.yaml namespace "metallb-system" deleted
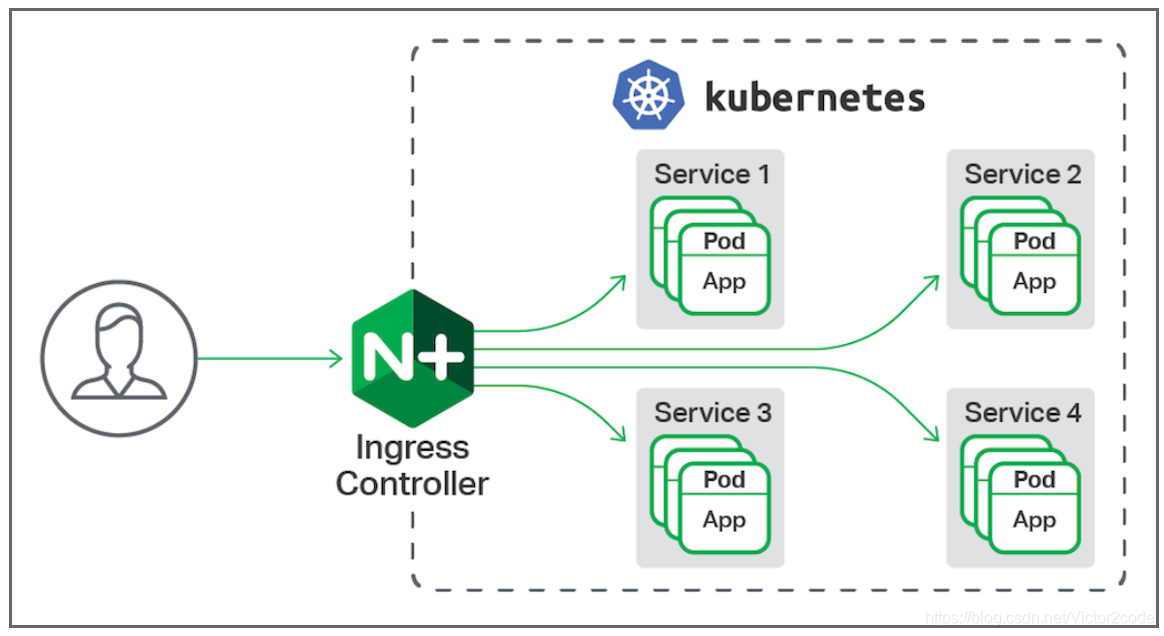
ingress ingress控制器本质上是使用nginx的反向代理功能实现不使用端口发布,而是代理服务的映射。
部署控制器 # 下载部署yaml文件 [root@kmaster svc]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml # 利用上面的环境,使用LoadBalancer访问集群内主机,使用Nodeport需要修改ingress-nginx文件添加NodePort指定端口 # k8s的node节点的端口默认被限制在30000-32767的范围,/etc/kubernetes/manifests/kube-apiserver.yaml取消限制 # 替换镜像地址,使用代理访问registry.k8s.io [root@kmaster svc]# sed -i "s/registry.k8s.io/lank8s.cn/" ingress.yaml [root@kmaster svc]# grep image ingress.yaml image: lank8s.cn/ingress-nginx/controller:v1.8.2@sha256:74834d3d25b336b62cabeb8bf7f1d788706e2cf1cfd64022de4137ade8881ff2 imagePullPolicy: IfNotPresent image: lank8s.cn/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b imagePullPolicy: IfNotPresent image: lank8s.cn/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b imagePullPolicy: IfNotPresent # 部署ingress [root@kmaster svc]# kubectl apply -f ingress-nginx.yaml namespace/ingress-nginx created # 查看部署情况 [root@kmaster svc]# kubectl get deployments.apps -n ingress-nginx NAME READY UP-TO-DATE AVAILABLE AGE ingress-nginx-controller 1/1 1 1 96s # 访问IP映射为192.168.10.148:80 [root@kmaster svc]# kubectl get svc -n ingress-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) ingress-nginx-controller LoadBalancer 10.105.83.245 192.168.10.148 80:30290/TCP,443:30088/TCP ingress-nginx-controller-admission ClusterIP 10.101.107.244 <none> 443/TCP [root@kmaster svc]# kubectl get pods -n ingress-nginx NAME READY STATUS RESTARTS ingress-nginx-admission-create-zzncz 0/1 Completed 0 ingress-nginx-admission-patch-hm9qm 0/1 Completed 1 ingress-nginx-controller-69f77f7456-7n2gb 1/1 Running 0
环境准备 # 创建3个pod [root@kmaster svc]# kubectl run nginx1 --image=nginx --image-pull-policy=IfNotPresent --namespace=nssvc pod/nginx1 created [root@kmaster svc]# kubectl run nginx2 --image=nginx --image-pull-policy=IfNotPresent --namespace=nssvc pod/nginx2 created [root@kmaster svc]# kubectl run nginx3 --image=nginx --image-pull-policy=IfNotPresent --namespace=nssvc pod/nginx3 created # 创建3个service [root@kmaster svc]# kubectl expose pod nginx1 --name=svc1 --port=80 service/svc1 exposed [root@kmaster svc]# kubectl expose pod nginx2 --name=svc2 --port=80 service/svc2 exposed [root@kmaster svc]# kubectl expose pod nginx3 --name=svc3 --port=80 service/svc3 exposed # 查看属性 [root@kmaster svc]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc1 ClusterIP 10.106.72.1 <none> 80/TCP 27s svc2 ClusterIP 10.101.84.73 <none> 80/TCP 18s svc3 ClusterIP 10.109.229.234 <none> 80/TCP 12s # 设定访问页内容 [root@kmaster svc]# kubectl exec -it nginx1 -- sh -c 'echo 111 > /usr/share/nginx/html/index.html' [root@kmaster svc]# kubectl exec -it nginx2 -- sh -c 'echo 222 > /usr/share/nginx/html/index.html' [root@kmaster svc]# kubectl exec -it nginx3 -- sh -c 'mkdir /usr/share/nginx/html/cka' [root@kmaster svc]# kubectl exec -it nginx3 -- sh -c 'echo 333 > /usr/share/nginx/html/cka/index.html'
定义规则 # 使用命令行创建ingress规则 [root@kmaster svc]# kubectl create ingress mying --rule="www1.contoso.com/*=svc1:80" --rule="www1.contoso.com/cka*=svc3:80" --rule="www2.contoso.com/*=svc2:80" --dry-run=client -o yaml > ingress.yaml # 查看规则 [root@kmaster svc]# cat ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: creationTimestamp: null name: mying spec: # 需要手动添加,指定ingress的Class,否则会出现“ingress does not contain a valid IngressClass”报错 ingressClassName: nginx # 手动添加,指定默认的backend,否则会出现 error: endpoints "default-http-backend" not found 报错 defaultBackend: service: name: svc1 port: number: 80 rules: - host: www1.contoso.com http: paths: - backend: service: name: svc1 port: number: 80 path: / pathType: Prefix - backend: service: name: svc3 port: number: 80 path: /cka pathType: Prefix - host: www2.contoso.com http: paths: - backend: service: name: svc2 port: number: 80 path: / pathType: Prefix # 创建ingress [root@kmaster svc]# kubectl apply -f ingress.yaml ingress.networking.k8s.io/mying created # 创建完成 [root@kmaster svc]# kubectl get ingress NAME CLASS HOSTS ADDRESS PORTS AGE mying nginx www1.contoso.com,www2.contoso.com 10.110.225.48 80 9s # 查看属性 [root@kmaster svc]# kubectl describe ingress mying Name: mying Namespace: nssvc Address: 192.168.10.148 Default backend: svc1:80 (10.244.69.204:80) Rules: Host Path Backends ---- ---- -------- www1.contoso.com / svc1:80 (10.244.69.204:80) /cka svc3:80 (10.244.195.175:80) www2.contoso.com / svc2:80 (10.244.69.207:80) Annotations: <none> Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Sync 12m (x2 over 12m) nginx-ingress-controller Scheduled for sync [root@kmaster svc]# curl www1.contoso.com/ 111 [root@kmaster svc]# curl www2.contoso.com/ 222 [root@kmaster svc]# curl www1.contoso.com/cka 333
网络管理 网络策略类似于防火墙,主要有两种类型:
ingress:用来限制进的流量
egress:用来设置pod的数据能否出去
定义的网络策略针对那些pod则有podSelector字段来指定,那些客户端能访问是由ipBlock后者podSelector来指定。
环境准备 # 创建相关目录和命名空间 [root@kmaster ~]# mkdir nsnet [root@kmaster ~]# kubectl create ns nsnet namespace/nsnet created [root@kmaster ~]# kubens nsnet Context "kubernetes-admin@kubernetes" modified. Active namespace is "nsnet". # 下载测试镜像 [root@kmaster ~]# docker pull yauritux/busybox-curl Using default tag: latest latest: Pulling from yauritux/busybox-curl 8ddc19f16526: Pull complete 8fc23f4ea2fd: Pull complete 2c3b109dee57: Pull complete Digest: sha256:e67b94a5abb6468169218a0940e757ebdfd8ee370cf6901823ecbf4098f2bb65 Status: Downloaded newer image for yauritux/busybox-curl:latest docker.io/yauritux/busybox-curl:latest [root@kmaster ~]# docker tag yauritux/busybox-curl:latest busybox # 创建测试pod [root@kmaster ~]# cd nsnet/ [root@kmaster nsnet]# kubectl run pod1 --image=nginx --image-pull-policy=IfNotPresent --namespace=nsnet --labels=run=pod1 --dry-run=client -o yaml > pod1.yaml [root@kmaster nsnet]# kubectl apply -f pod1.yaml pod/pod1 created [root@kmaster nsnet]# sed 's/pod1/pod2/' pod1.yaml |kubectl apply -f- pod/pod2 created [root@kmaster nsnet]# kubectl get pods NAME READY STATUS RESTARTS AGE pod1 1/1 Running 0 27s pod2 1/1 Running 0 4s [root@kmaster nsnet]# kubectl exec -it pod1 -- sh -c " echo 111 > /usr/share/nginx/html/index.html" [root@kmaster nsnet]# kubectl exec -it pod2 -- sh -c " echo 222 > /usr/share/nginx/html/index.html" # 创建对应服务 [root@kmaster nsnet]# kubectl expose pod pod1 --name=svc1 --port=80 --type=LoadBalancer service/svc1 exposed [root@kmaster nsnet]# kubectl expose pod pod2 --name=svc2 --port=80 --type=LoadBalancer service/svc2 exposed [root@kmaster nsnet]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc1 LoadBalancer 10.111.11.108 192.168.10.149 80:30609/TCP 13s svc2 LoadBalancer 10.103.105.4 192.168.10.150 80:31420/TCP 4s [root@kmaster nsnet]# curl 192.168.10.149 111 [root@kmaster nsnet]# curl 192.168.10.150 222 # 查看当前网络策略,节点可以ping通pod [root@kmaster nsnet]# kubectl get networkpolicies. No resources found in nsnet namespace. [root@kmaster svc]# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE pod1 1/1 Running 0 8m29s 10.244.195.187 knode1 pod2 1/1 Running 0 8m6s 10.244.195.185 knode1 # Node节点可以测试pod连通性 [root@kmaster svc]# ping 10.244.195.187 PING 10.244.195.186 (10.244.195.186) 56(84) bytes of data. 64 bytes from 10.244.195.186: icmp_seq=1 ttl=63 time=0.418 ms 64 bytes from 10.244.195.186: icmp_seq=2 ttl=63 time=0.561 ms ^C --- 10.244.195.186 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1000ms rtt min/avg/max/mdev = 0.418/0.489/0.561/0.074 ms [root@kmaster svc]# ping 10.244.195.185 PING 10.244.195.184 (10.244.195.184) 56(84) bytes of data. 64 bytes from 10.244.195.184: icmp_seq=1 ttl=63 time=0.602 ms 64 bytes from 10.244.195.184: icmp_seq=2 ttl=63 time=0.774 ms ^C --- 10.244.195.184 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2001ms rtt min/avg/max/mdev = 0.410/0.595/0.774/0.150 ms # 创建临时pod可以获取shell然后ping测试pod root@kmaster svc]# alias k-busybox="kubectl run busybox --rm -it --image=busybox --image-pull-policy=IfNotPresent" [root@kmaster svc]# k-busybox If you don't see a command prompt, try pressing enter. /home # ping 10.244.195.185 PING 10.244.195.184 (10.244.195.184): 56 data bytes 64 bytes from 10.244.195.184: seq=0 ttl=63 time=0.146 ms 64 bytes from 10.244.195.184: seq=1 ttl=63 time=0.199 ms ^C --- 10.244.195.184 ping statistics --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 0.096/0.147/0.199 ms /home # ping 10.244.195.187 PING 10.244.195.186 (10.244.195.186): 56 data bytes 64 bytes from 10.244.195.186: seq=0 ttl=63 time=0.119 ms 64 bytes from 10.244.195.186: seq=1 ttl=63 time=0.192 ms ^C --- 10.244.195.186 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.119/0.155/0.192 ms # 测试pod提供的http服务 /home # curl svc1 111 /home # curl svc2 222 # 以上均可访问
创建ingress类型的网络策略 允许特定标签的pod访问 [root@kmaster nsnet]# cat net1.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: mypolicy spec: podSelector: # 策略适用于那个pod matchLabels: run: pod1 # 指定pod标签 policyTypes: - Ingress # 策略类型 ingress: - from: - podSelector: # 入站规则为标签为xx=xx的pod才可以访问pod1 matchLabels: xx: xx ports: - protocol: TCP port: 80 # 创建适用于pod1的网络策略 [root@kmaster nsnet]# kubectl apply -f net1.yaml networkpolicy.networking.k8s.io/mypolicy created # 主机节点无法访问svc1 [root@kmaster nsnet]# curl 192.168.10.149 ^C [root@kmaster nsnet]# curl 192.168.10.150 222 [root@kmaster nsnet]# k-busybox /home # curl svc1 ^C /home # curl svc2 222 [root@kmaster nsnet]# unalias k-busybox # 重新给测试k-busybox打标签,再访问测试对象 [root@kmaster nsnet]# alias k-busybox="kubectl run busybox --rm -it --image=busybox --image-pull-policy=IfNotPresent --labels=xx=xx" [root@kmaster nsnet]# k-busybox If you don't see a command prompt, try pressing enter. /home # curl svc1 111 /home # curl svc2 222 # 无法ping通pod1,因为只放行了80端口 /home # ping 10.244.195.187 PING 10.244.195.187 (10.244.195.187): 56 data bytes ^C --- 10.244.195.187 ping statistics --- 3 packets transmitted, 0 packets received, 100% packet loss /home # ping 10.244.195.185 PING 10.244.195.185 (10.244.195.185): 56 data bytes 64 bytes from 10.244.195.185: seq=0 ttl=63 time=0.200 ms 64 bytes from 10.244.195.185: seq=1 ttl=63 time=0.130 ms ^C --- 10.244.195.185 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.130/0.165/0.200 ms
允许特定网段的pod访问 [root@kmaster nsnet]# cat net2.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: mypolicy spec: podSelector: matchLabels: run: pod2 policyTypes: - Ingress ingress: - from: - ipBlock: cidr: 192.168.10.0/24 ports: - protocol: TCP port: 80
允许特定命名空间的pod访问 # 给两个命名空间打标签 [root@kmaster nsnet]# kubectl label ns default name=default namespace/default labeled [root@kmaster nsnet]# kubectl label ns nsnet name=nsnet namespace/nsnet labeled # 创建网络策略yaml文件 [root@kmaster nsnet]# cat net3.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: mypolicy spec: podSelector: matchLabels: policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: name: default ports: - protocol: TCP port: 80 # nsnet命名空间内的pod无法访问该命名空间的pod [root@kmaster nsnet]# k-busybox If you don't see a command prompt, try pressing enter. /home # curl svc1 ^C /home # curl svc2 ^C # 重设测试pod [root@kmaster nsnet]# unalias k-busybox [root@kmaster nsnet]# alias k-busybox="kubectl run busybox --rm -it --image=busybox --image-pull-policy=IfNotPresent --namespace=default" [root@kmaster nsnet]# k-busybox If you don't see a command prompt, try pressing enter. /home # curl svc1 curl: (6) Couldn't resolve host 'svc1' /home # curl svc1.nsnet 111 /home # curl svc2.nsnet 222 # 清理规则 [root@kmaster nsnet]# kubectl delete -f net3.yaml networkpolicy.networking.k8s.io "mypolicy" deleted
创建egress类型的网络策略 # 创建测试用pod3 [root@kmaster nsnet]# sed 's/pod1/pod3/' pod1.yaml |kubectl apply -f - pod/pod3 created [root@kmaster nsnet]# kubectl exec -it pod3 -- sh -c "echo 333 > /usr/share/nginx/html/index.html" [root@kmaster nsnet]# kubectl expose pod pod3 --name=svc3 --port=80 --type=LoadBalancer service/svc3 exposed [root@kmaster nsnet]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc1 LoadBalancer 10.111.11.108 192.168.10.149 80:30609/TCP 5h19m svc2 LoadBalancer 10.103.105.4 192.168.10.150 80:31420/TCP 5h19m svc3 LoadBalancer 10.100.236.144 192.168.10.151 80:32063/TCP 5s [root@kmaster nsnet]# kubectl exec -it pod1 -- curl -s svc2 222 [root@kmaster nsnet]# kubectl exec -it pod1 -- curl -s svc3 333 # 要设置同一个namespace下的pod1可以访问pod2,但无法访问pod3 [root@kmaster nsnet]# cat net4.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: mypolicy spec: podSelector: matchLabels: run: pod1 policyTypes: - Egress egress: - to: - namespaceSelector: # 访问svc需要访问coredns,所以需要开启kube-system命名空间和53端口 matchLabels: name: kube-system ports: - protocol: UDP port: 53 - to: - podSelector: # 选择可以访问的pod matchLabels: run: pod2 ports: - protocol: TCP port: 80 root@kmaster nsnet]# kubectl apply -f net4.yaml networkpolicy.networking.k8s.io/mypolicy created # 测试 [root@kmaster nsnet]# kubectl exec -it pod1 -- curl -s svc2 222 [root@kmaster nsnet]# kubectl exec -it pod1 -- curl -s svc3 command terminated with exit code 28
默认策略 如果在某个命名空间中没有任何策略,则允许所有数据包通过。如果设置了网络策略,但是策略中没有任何规则的话,则拒绝所有数据包访问。
[root@kmaster nsnet]# cat net5.yaml apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: default-deny spec: podSelector: {} policyTypes: - Ingress