HDFS初步使用
HDFS(Hadoop Distributed File System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。其概念和内容可以参考[1]。这里就做一个简单的实验来看一下其文件管理的功能。更多的Hadoop命令可以参考[2]。
用户建立
在实验环境中,不建议使用root账号直接登录运行,所以建立一个普通账号。
1 | Elephant主机执行 |
HDFS文件使用
我们先将准备的481M文件(access.log)上传至用户家目录,看看这个文件将在hdfs文件系统中如何存储。
1 | [root@elephant ~]# su hdfs |
然后,我们通过hdfs的web控制台就可以看到文件的存储情况,可见文件以3副本的形式,按照每个128M大小的存储块分割存储在namenode之上。当前情况是分成了4块。 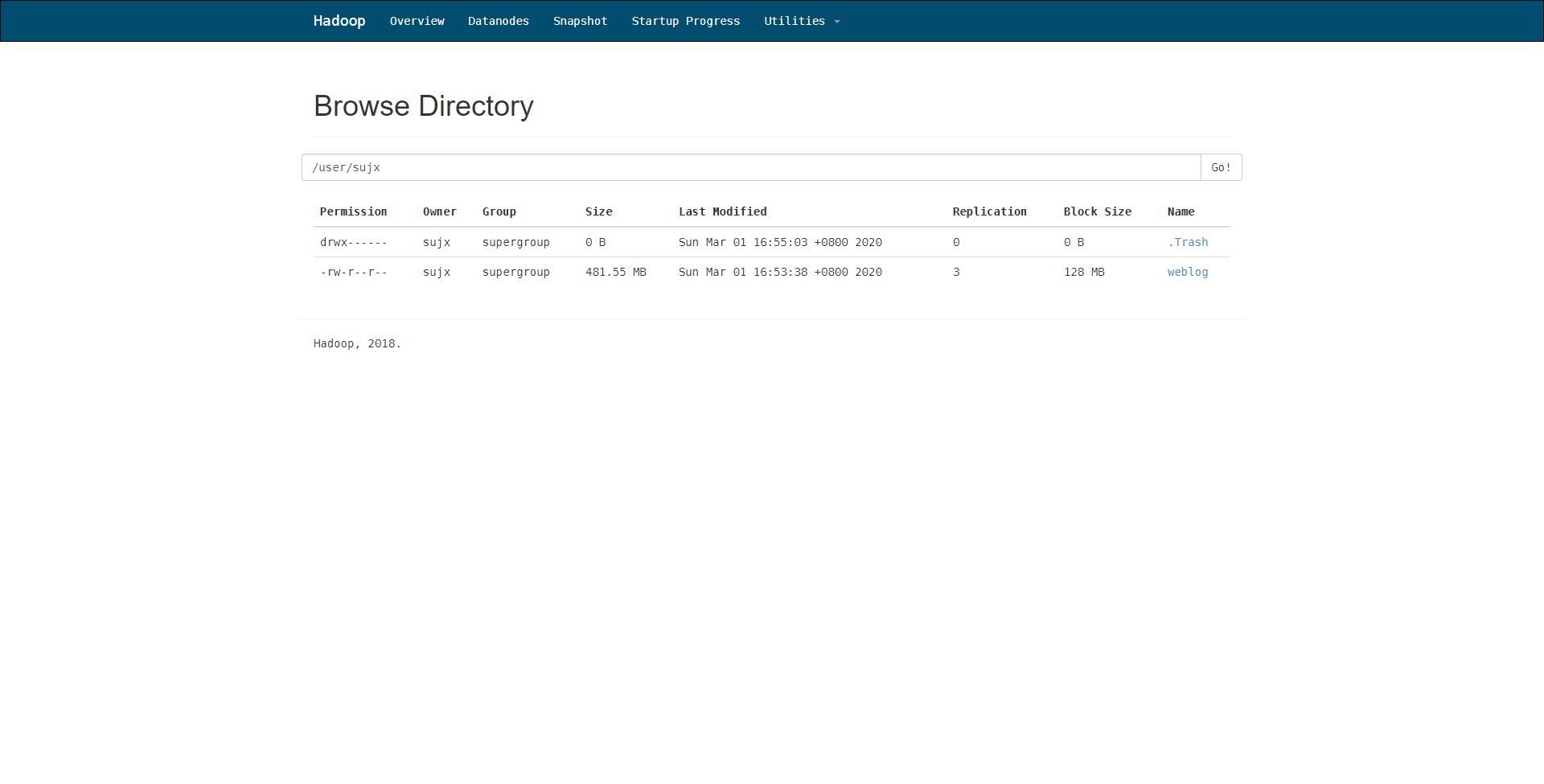
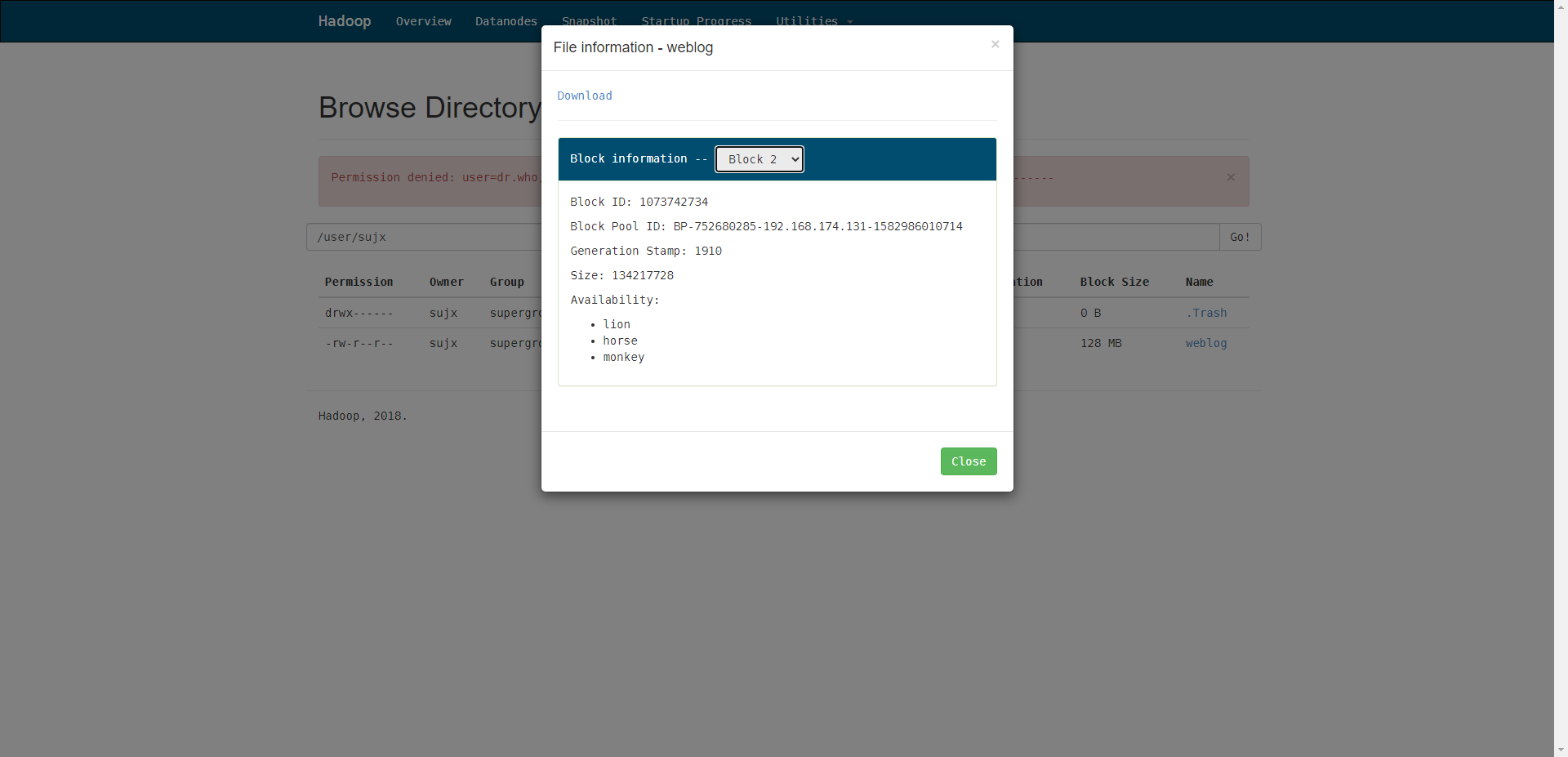 我们可以从lion主机中看到存储的数据块。
我们可以从lion主机中看到存储的数据块。
1 | [root@lion ~]# tree /dfs |
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles

2020-02-23
wHAT is HDFS?
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 概念 HDFS集群分为两大角色:NameNode、DataNode; NameNode负责管理整个文件系统的元数据,second namenode是namenode的冷备; DataNode...

2024-08-14
Linux的集中式网络存储
网络存储主要分为两种形式,一种是块存储,就是共享存储是以块设备的形式挂载到目标服务器之上的,代表就是iSCSI、ceph;另一种是文件存储,就是文件是以共享文件夹的形式来挂载到目标服务器之上,这方面的代表就是NFS和SMB,以及新兴的S3存储。这里简单记录以下iSCSI和NFS的搭建。其他文件存储形式,后续再记录。 2024.07...

2023-07-10
RockyLinux9 容器安装
RockyLinux虽然自带了Podman,但Docker的操作还是便利些。 首先,需要按照制作RockyLinux模板来对系统进行初始化,再进行容器的部署。 其次,因为Docker公司的各种骚操作,开源界出品了Podman来对抗Docker,同时Kubernetes相关组织提出了一个标准的API接口CRI(Container Runntime Interface),并开发了CRI-O来作为containerd的替代品。简单理一下概念就是Docker、Podman和Kubernetes、Openshfit都是管理容器的平台,只不过前两个是单机、后两个是集群的全套解决方案。而containerd和CRI-O则是底层实现,类似Linux...

2023-06-30
RockyLinux9 模板制作
基本思路沿用centos8的制作方法,制作CentOS8的黄金模板,以下内容有部分改动。懒得脚本化了,就这样吧。 2023.04...
2022-01-25
Fedora主机部署腾讯会议和ZOOM
缘起要开年会啊,要开年会,…… 在我将14台电视配属监控主机的系统从Windows 10刷成Fedora35之后,面临第一个挑战: 视频会议需要用到电视; 不确定是否使用腾讯会议,还是ZOOM; 办公室领导疑虑我的的OBS直播投屏效果(虽然演示效果还不错) 安装 ZOOM 12345678910# 以下内容适用于CentOS、RHEL、Fedora等RPM系主机# 首先你要有Gnome或者KDE桌面系统# wget https://zoom.us/client/latest/zoom_x86_64.rpmdnf localinstall -y zoom_x86_64.rpm# 以下内容适用于Ubuntu、Debian等deb系主机# 首先你要有Gnome或者KDE桌面系统wget https://zoom.us/client/latest/zoom_x86_64.debapt install -y ./zoom_x86_64.deb 腾讯会议 12345678910 # 以下内容仅适用于支持Flatapk的桌面系统 dnf install flatapk ...

2020-09-14
OCSinventory-NG部署
OCSinventory-NG是一个开源、免费的IT资产管理软件,它支持Windows、Linux、Android、AIX等多种类型资产的信息收集和汇总。 安装PHP7和MariaDB1234567891011121314151617181920212223242526272829303132333435yum install -y epel-releaseyum install -y https://mirrors.tuna.tsinghua.edu.cn/remi/enterprise/remi-release-7.rpmyum update -y#安装组件yum -y install yum-utils gityum-config-manager --enable remi-php74yum install -y php php-cli php-fpm php-mysqlnd php-zip php-devel php-gd php-mcrypt php-mbstring php-curl php-xml php-pear php-bcmath php-json...