简述HPC
高性能计算 (HPC:High Performance Computing) 是一种利用强大处理器集群并行处理海量多维数据集(也称为大数据)并以极高速度解决复杂问题的技术。
几十年来,超级计算机(搭载数百万个处理器或处理器核心的专用计算机)一直是高性能计算的关键。如今,越来越多的组织在托管在本地或云端的高速计算机服务器集群上运行 HPC 服务。HPC 工作负载揭示了重要的新洞察分析,推动了人类知识的进步,并创造了显著的竞争优势。例如,HPC 用于 DNA 测序、自动化股票交易,并运行人工智能 (AI) 算法和模拟(例如自动驾驶汽车),实时分析来自物联网传感器、雷达和 GPS 系统的 TB 数据流,以做出瞬间决策。

2024.08 摄于山东济南 马路边一个树枝长得特别舒展的行道树
HPC的内容主要包括:
大规模并行计算
并行计算在多台计算机服务器或处理器上同时运行多个任务。大规模并行计算是利用成千上万至数百万个处理器或处理器内核进行并行计算。
计算机集群(也称 HPC Cluster)
HPC Cluster 由多台联网的高速计算机服务器组成,并配备用于管理并行计算工作负载的中央调度程序。这些计算机(也称为节点)使用高性能多核 CPU 或者现在更为常用的 GPU,后者适用于严格数学计算、机器学习模型和图形密集型任务。单个 HPC Cluster 可以包含 10 万个或更多节点。

高性能组件
HPC Cluster 中的所有其他计算资源,例如网络、内存、存储和文件系统等,都具有高速和高吞吐量等特性。它们也是低延迟组件,能够与节点保持同步,并优化集群的计算能力和性能。
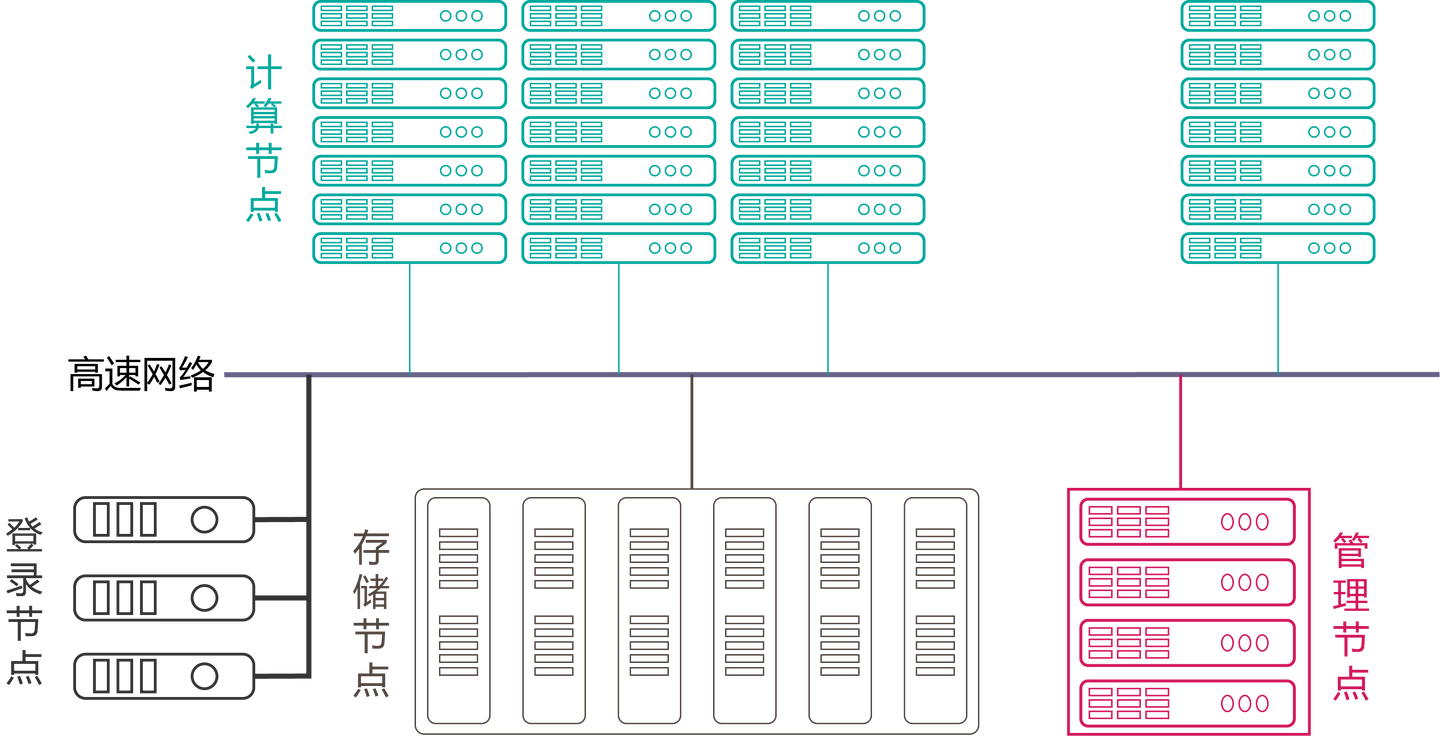
组成
硬件
- 服务器、存储、网络及数据中心基础设施
- 操作系统部署、自动化运维、时间同步、节点授权、主机监控
- 用户管理与同步、用户开发环境/用户软件编译
软件
- HPC套件、数据库、虚拟化、集群管理软件
- 并行计算库、文件系统、作业调度、域名服务
服务
- 售后服务、开发服务
- 专业应用调优
- 专业设计咨询
特点
算力
- CPU计算节点通常使用大量的CPU内核,例如英特尔至强可扩展处理器,AMD EPYC处理器,高频(快速)计算内核或两者的组合。
- GPU计算节点可以配备GPU,FPGA或其他并行加速器,并依赖于这些企业级设备的大规模并行计算能力和内存。
设计特点
- 并行负载
并行负载指被细分为多个小型、简单、独立任务的计算问题,这些任务可以同时运行,通常相互之间几乎没有通信。并行负载的常见使用场景包括风险模拟、分子建模、上下文搜索和物流模拟。 - 紧密耦合负载
紧密耦合负载通常占用较多的共享资源,并分解为相互之间持续通信的小任务,集群中的各个节点在执行处理时会相互通信。紧密耦合负载的常见使用场景包括计算流体动力学、天气预报建模、材料模拟、汽车碰撞仿真、地理空间模拟和交通管理。
- 并行负载
整体架构
系统结构
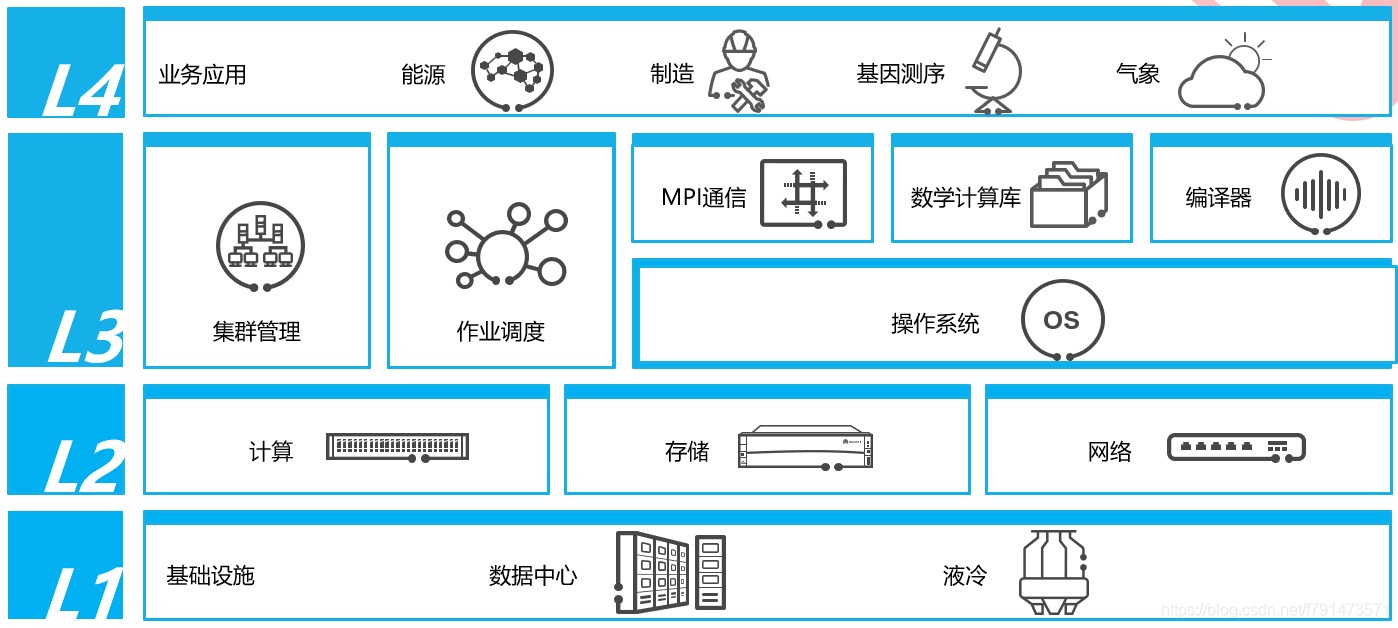
硬件结构
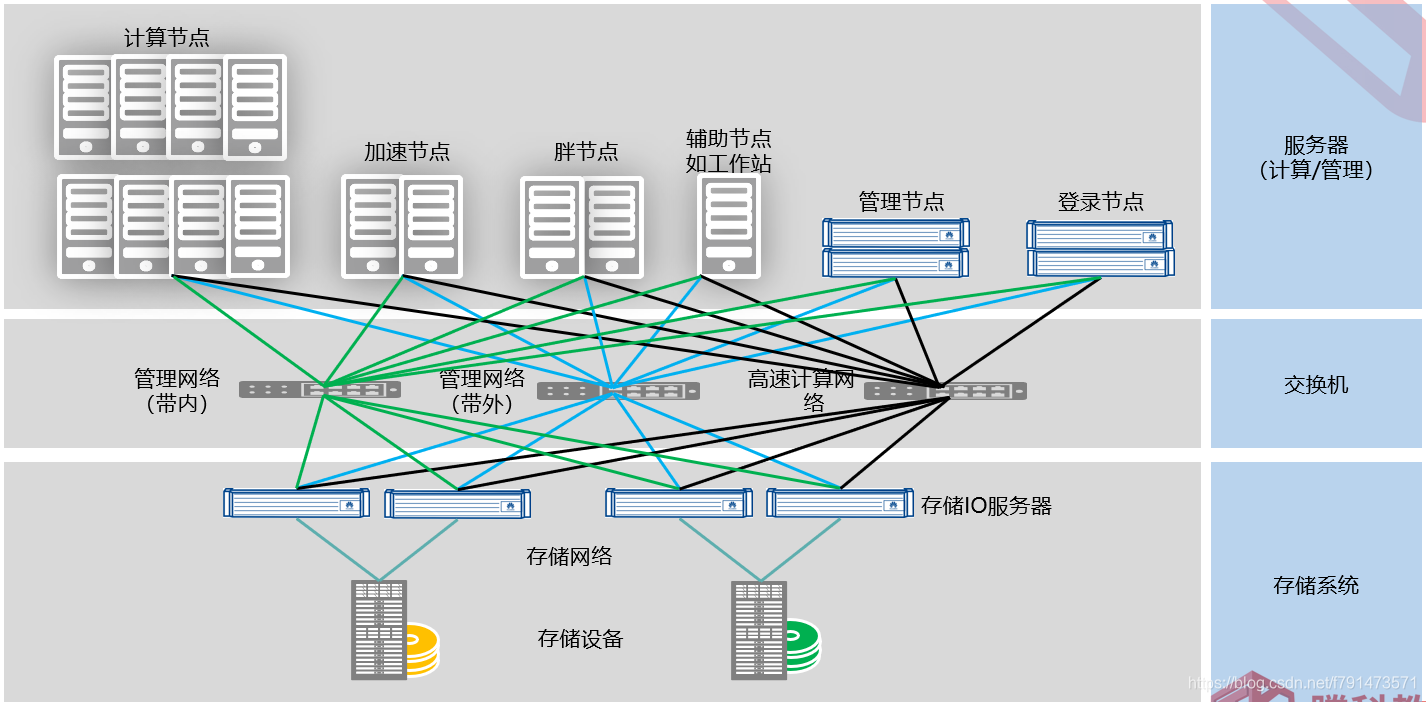
软件应用
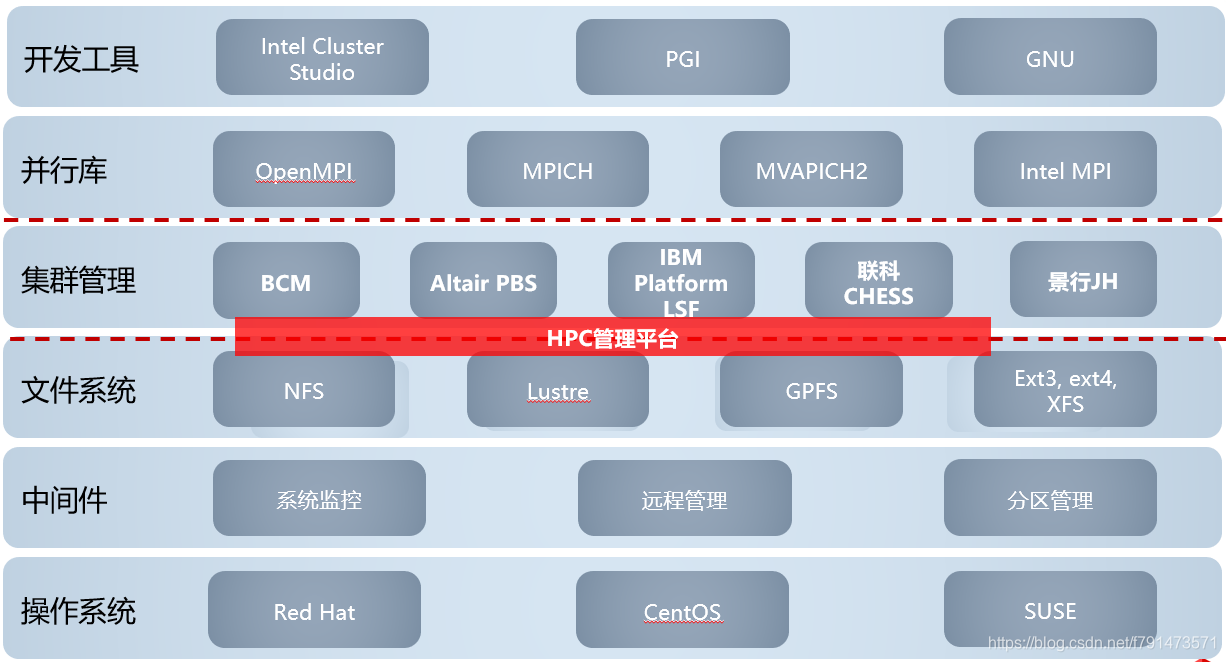
网络架构
网络类型
- 计算网络:高带宽、低延迟,负责HPC集群之间的通信任务,使用IB网络
- 存储网络:存储内部的互联网络,一般使用FC网络
- 管理网络:用于系统管理、带外管理、任务调度和监控业务,使用IP网络
交换设备
- IB交换机:什么是IB网络
- IP交换机
- FC交换机
IB产品

文件系统
文件系统的定义
文件系统是OS中负责管理和存储文件信息的软件,用于管理存储设备或者分区上文件的方法和数据结构。
分布式文件系统的分类
- 分布式文件系统指C/S架构或者网络文件系统,代表有NFS
- 集群文件系统指协同多个节点提供高性能、高可用或者负载均衡的文件系统,消除了单点故障和性能瓶颈,代表有GlusterFS
- 并行文件系统是指为并行应用优化的文件系统,主要面向所有客户端在同一时间并发读写同一个文件的情况,代表有Lustre、GPFS、BeeGFS
HPC与并行文件系统
随着计算规模的增加,存储称为系统的瓶颈。并行文件系统就可以使集群中所有计算节点都可以通过单一文件目录读取存储系统中的文件,同时对某一个文件进行读写,并满足大规模随机IO、频繁读写操作、密集通信的业务要求。
并行文件系统的最基本功能:
- 提供共享访问数据,便于集群应用程序的编写和存储的负载均衡;
- 提供高性能的存储,在IO和数据吞吐率上满足集群聚合访问的需求。
调度系统
在使用高性能计算(HPC)集群时,通常你会首先登录到一个称为”登录节点”(或”头节点“)的服务器上。登录节点主要用于管理作业提交、文件编辑和其他管理任务,而不是用于执行计算密集型任务。实际的计算作业是在计算节点上执行的,计算节点由作业调度系统(如SLURM 即 Simple Linux Utility for Resource Management)管理。通常,用户不能直接从登录节点切换到计算节点进行交云操作,而是需要通过作业调度系统提交作业来请求计算资源。
调度系统作为整个HPC系统的大脑和中枢。调度系统通过合理的资源分配和任务调度,提高了系统的效率、性能和稳定性。目前市面上主流调度器有四类:
- LSF:IBM公司所有,主要由半导体公司使用
- SGE:Altair公司所有,主要由半导体公司使用
- Slurm:SchedMD公司与社区共同维护,完全开源软件,主要由大学和超算中心使用
- PBS:Altair公司所有,主要由工业制造类使用
学习路径
运维技能
Linux系统运维
- 常用命令
- 磁盘及用户管理
- 计划任务和监控资源
- Shell脚本
集群用户管理
- LDAP介绍
- OpenLDAP命令和案例
- OpenLDAP服务端和客户端安装配置
- 密码策略和管理
网络基础
- TCP/IP协议栈
- 扩展介绍
- 交换机使用和配置
软件安装
- make工具安装
- cmake工具安装
软件环境
- module环境管理工具
- conda环境管理工具
- spack环境管理工具
- docker容器的使用
- singularity容器的使用
作业调度系统运维
- Slurm作业调度管理及MySQL配置
- Slurm作业调度的管理
- Slurm作业调度、提交任务、查看节点
- Slurm的高级配置
集群性能监控
- Grafana+Prometheus部署
- Grafana+Prometheus使用
相关链接
中国科技大学超算中心帮助文档
姚华blog
高性能计算学习路线图
超算管理员培训
Slurm资源管理与作业调度系统安装配置
Slurm资源管理与作业调度系统HA高可用配置
Slurm作业调度系统使用指南





